The DPDK Project has had an active third quarter thus far with the DPDK Userspace Summit in September, release of 20.11 release (the biggest DPDK release yet!), and the Governing Board focused on 2021 planning and budgeting during an October 13 virtual meeting.
A release candidate (RC3) for 20.11 went out last week, and turned out to be one of the biggest releases to date for DPDK. Notable updates include:
-
- New LTS with v21 ABI
- 800+ new patches already applied to main
- 890+ in patchwork
- Going to be a large release!
- More details: http://doc.dpdk.org/guides/rel_notes/release_20_11.html
We continue to seek additional DPDK reviewers and are looking for volunteers. If you are an active contributor to DPDK, we invite you to help review your fellow contributors’ patches; help us collectively improve DPDK releases.
DPDK Userspace Summit
Capping off a tumultuous 2020, the DPDK community came together virtually for the DPDK Userspace Summit, September 22-23rd. With over 550 registrants and 250 active participants from over 46 countries, the ecosystem came together for what was one of the largest DPDK Userspace Summits to date. We would like to extend a thank you to all the speakers, planning committee members, as well as and Arm for sponsoring the event. Technical Presentations and videos are available in the event archive: https://www.dpdk.org/event/dpdk-userspace-summit/
Happy 10 years, DPDK!
DPDK project celebrated it’s 10 year anniversary during the virtual summit, marking the occasion with a new celebratory webpage, with excerpts and pictures from across the community: https://www.dpdk.org/10th-anniversary/
Please join us in also recognizing this year’s recipients of the 2020 Community Awards. https://www.dpdk.org/blog/2020/09/27/dpdk-community-awards-recognize-development-excellence/
By the Numbers
Looking back at the year, we have a lot to be proud of as a community:
- 2,086 Commits, 199 Authors, 18 Repositories
- Releases:
- 20.11 (Nov), 20.08 (Aug), 20.05 (May), 20.02 (Feb)
- 19.11.5 (LTS) (Sept), DPDK 18.11.10 (LTS) (Sept), DPDK 17.11.10 (LTS) (Feb)
- Membership Revenue saw a 14% increase over 2019
- Events: DPDK virtual userspace 570 registered, 250 active participants
- Community Lab testing coverage has expanded, and exceeded the original target set by the Testing Working Group.
- DPDK website pageviews: 36,500 (over past 90 days)
- Publication of the DPDK White paper and video series
- Twitter followers over 1060+
Other Notable Updates
Upcoming Events: With the prevailing impact of the global pandemic, DPDK continues to monitor and assess the viability of hosting an in person gathering; as of today, we have moved to a virtual event calendar and anticipate our next virtual gathering towards the end of Q1, 2021. Look forward to an event and CFP announcement soon.
Budget: The Board has updated the budget to reflect our real-time changes as a result of the impact of COVID-19 and is currently discussing 2021 budget priorities and alignment. We will provide an update once the preliminary budget has been made.
Lab: A sub-team has been working with the DPDK Community Lab team, including UNH-IOL, to expand the testing coverage provided by the Community Lab. We are happy to report that under the guidance of the Technical Steering Committee, the Testing Group has exceeded their targeted testing coverage goals of 40%, with over 56% Functional test coverage in the community lab. The Community Lab team continues to refine its practices and plans to expand in the coming months.
Member Outreach: No changes to membership this quarter. If you have any suggestions for companies or individuals that we should reach out to, please let us know.
Thank you for your continued engagement with the DPDK community! We hope everyone is staying healthy and keeping busy during these uncertain times.
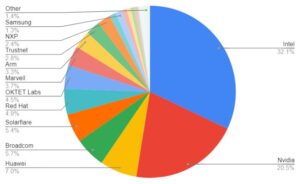

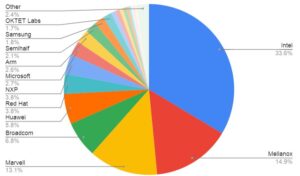
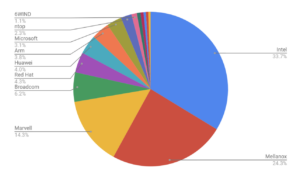
 Lastly, for the currently operating testing, is the community lab, hosted at the UNH-IOL. Testing in the community lab is also tracking both the main branch and submitted patches, providing a combination of compile, unit testing, functional testing, and performance testing. The compile and unit testing also add one additional dimension, with some cooperation to downstream projects, such as Open vSwitch and SPDK, providing early detection of a patch breaking outside of DPDK directly. For the functional and performance testing, the lab hosts a number of “bare-metal” systems with NICs provided by DPDK member companies, including Broadcom, Intel, Mellanox, and NXP currently. The performance testing runs a throughput test on each NIC (in some cases there are multiple speeds or hardware variants included), checking for a drop in forwarding performance from a well known reference. Gold and Silver DPDK member companies are eligible to submit hardware for hosting in the community lab and are strongly encouraged to do so by the governing and tech boards of DPDK, as this directly expands the testing coverages. Functional testing is the newest and growing aspect within the community lab output, adding more tests running on “bare-metal”, based on the DTS (DPDK Test Suite) project. Aiming to provide majority coverage for the NIC features list. The community lab results also feed directly into the patchwork system, with additional information available on the lab portal as well:
Lastly, for the currently operating testing, is the community lab, hosted at the UNH-IOL. Testing in the community lab is also tracking both the main branch and submitted patches, providing a combination of compile, unit testing, functional testing, and performance testing. The compile and unit testing also add one additional dimension, with some cooperation to downstream projects, such as Open vSwitch and SPDK, providing early detection of a patch breaking outside of DPDK directly. For the functional and performance testing, the lab hosts a number of “bare-metal” systems with NICs provided by DPDK member companies, including Broadcom, Intel, Mellanox, and NXP currently. The performance testing runs a throughput test on each NIC (in some cases there are multiple speeds or hardware variants included), checking for a drop in forwarding performance from a well known reference. Gold and Silver DPDK member companies are eligible to submit hardware for hosting in the community lab and are strongly encouraged to do so by the governing and tech boards of DPDK, as this directly expands the testing coverages. Functional testing is the newest and growing aspect within the community lab output, adding more tests running on “bare-metal”, based on the DTS (DPDK Test Suite) project. Aiming to provide majority coverage for the NIC features list. The community lab results also feed directly into the patchwork system, with additional information available on the lab portal as well: