Thomas Monjalon, a maintainer at NVIDIA, opened the summit in Bangkok by emphasizing the importance of the community in the project. He highlighted the role of contributors like Ben Thomas, who handles marketing, and encouraged attendees to share their stories and get involved.
Thomas provided logistical details about and discussed the project’s history, noting its growth since its inception in 2010 and the support from the Linux Foundation. Looking ahead, Monjalon outlined priorities such as better public cloud integration, enhanced security protocols, and contributions to AI.
He stressed the long-term benefits of contributing to open source, including thorough documentation and community support, and noted that being part of the community can help individuals find new job opportunities.
Feng Chengwen from Huawei Technologies presented on the UACCE (Unified Accelerator Framework) integrated into DPDK. UACCE was designed to simplify usage and enhance performance and security for user space I/O and DMA operations without system involvement. It was upstreamed in version 5.7 of the Linux kernel and the latest DPDK release 24.03, allowing accelerators to access memory regions directly and eliminating address translation.
Key objectives include high performance, simplified usage, and security, with support for multiprocess memory acceleration and on-demand resource usage. UACCE addresses performance issues such as page faults and NUMA balancing using techniques like CPU pre-access and memory binding.
It is used in both host systems and virtual machines, though some features for virtual machines are still in development. Feng encouraged other developers to adopt UACCE, highlighting its broader application potential, and discussed future enhancements to integrate more devices into DPDK using the UACCE framework.
The presentation introduces the ZXDH DPU driver, highlighting its features, applications, and product portfolio. The DPU system framework includes modules for high-speed network interfaces, PCI connectivity, and advanced packet processing, supporting RDMA, NVMe protocols, and multiple accelerators for security and storage.
It enhances network and storage performance by offloading tasks from the host CPU, supporting virtualization, AI, and edge computing, with capabilities like TLS encryption. An example of offloading security group functions to the DPU demonstrates reduced CPU load and increased processing efficiency.
The product portfolio supports up to 5 million IOPS and 100 million packets per second, with ongoing development to improve TCP protocol handling and storage acceleration.
Yuanhan Liu from ByteDance introduces Libtpa, a user-space TCP/IP stack developed from scratch. The presentation discusses its background, design, testing, and performance.
Traditional kernel-based TCP/IP stacks have inefficiencies and overhead, and existing user-space TCP stacks face problems like breaking the kernel stack, limited zero-copy support, and inadequate testing and debugging tools.
Libtpa addresses these issues by allowing coexistence with the kernel stack, supporting multiple user-space instances, optimizing performance with zero-copy, and providing extensive testing and debugging capabilities.
Its architecture supports high throughput and low latency, achieving significant performance improvements. Libtpa includes over 200 unit tests and advanced debugging tools to ensure stability and ease of troubleshooting in production environments.
Ilan Raman and his colleagues from Aviz Networks developed 5G packet processing applications using DPDK to manage complex 4G and 5G traffic on commodity hardware efficiently. Aviz Networks, founded in 2019 and operating in the USA, India, and Japan, focuses on providing open-source solutions for telecom operators.
They address challenges in monitoring evolving mobile technologies, scaling solutions horizontally, and reducing TCO through software-driven approaches. A primary use case is 5G correlation, which enhances network performance monitoring by correlating control and user traffic. Deployment involves DPDK-based applications on commodity hardware, processing high-bandwidth traffic, and extracting valuable metadata for insights and capacity planning.
The architecture uses a run-to-completion model, distributing functions across dedicated cores to handle various traffic types, with scalability achieved through RSS functionality in NICs. Practical learnings include configuring RSS for different packet types, ensuring symmetric load balancing, using per-core hash tables, isolating DPDK cores from the Linux kernel, and performing deep packet parsing in software.
Aviz Networks leveraged DPDK’s packet manipulation libraries for handling custom headers and achieved better performance through memory optimizations and CPU isolation.
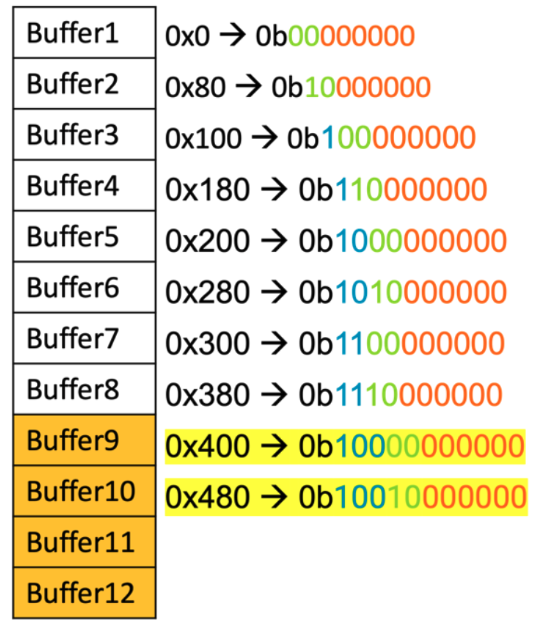
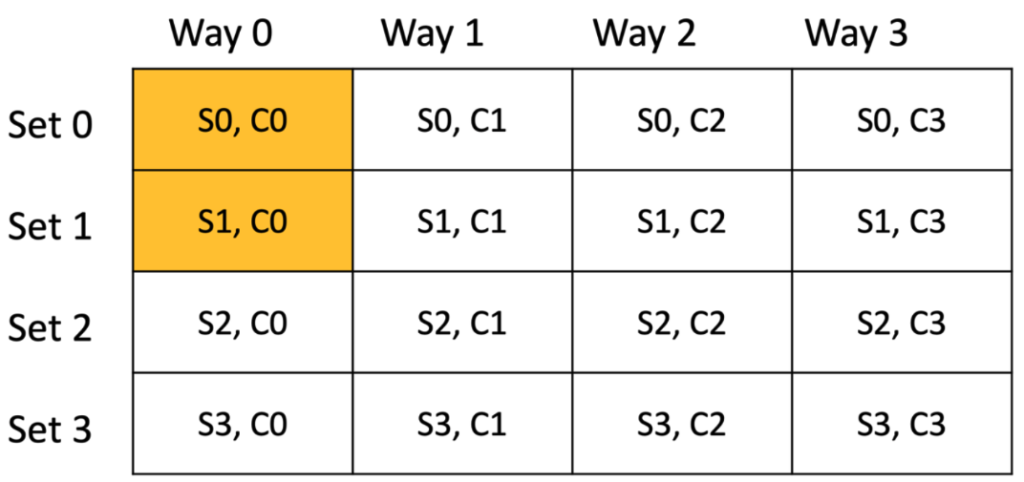
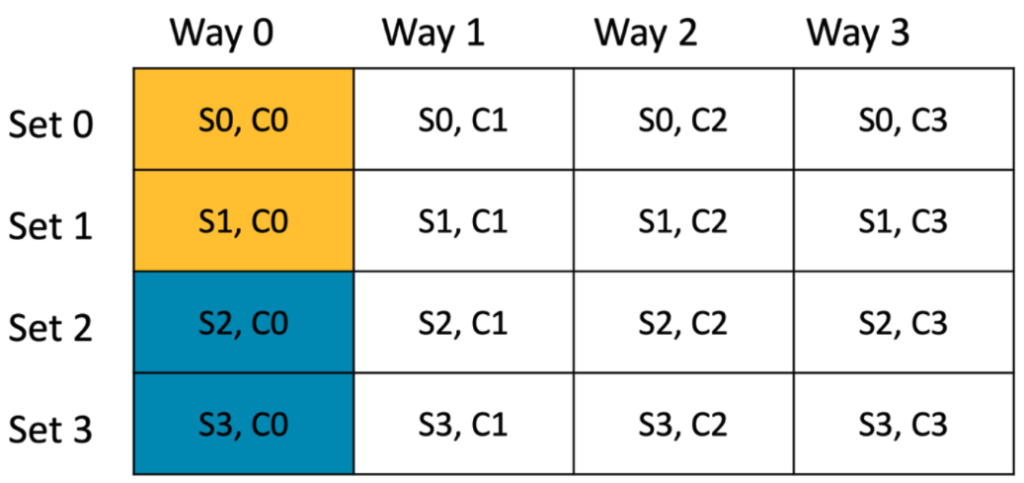
The presentation by Suanming Mou from NVIDIA focused on optimizing the unified representer in large-scale ports within DBK switch models. Initially, the high memory and CPU usage due to the need to poll all represent ports when packets missed hardware flow rules was a significant challenge.
The optimization approach involved setting “represent matching” to zero, directing all packets to a single uplink represent port, and copying the source port ID to packet metadata for identification in the hypervisor. This change reduced the need for extensive memory allocation and CPU polling as traffic was handled through a single proxy port.
The implementation of new flow rules for this setup resulted in substantial memory savings, decreasing from over 800 MB to around 332 MB, and improved packets per second (PPS) performance, increasing from 20 Mega PPS to 27.5 Mega PPS due to optimized polling and reduced cache misses. Overall, the optimization streamlined the polling process and significantly enhanced resource efficiency and performance in managing large-scale port traffic.
The presentation addresses the challenges encountered when transitioning applications from bare metal to container environments, emphasizing issues like reduced throughput, increased packet processing time, fluctuating latencies, and unpredictable performance with multiple container instances.
Root causes of these problems include limited access to hardware resources, library and compiler version mismatches, lack of specific patches, and performance variations based on hardware architecture and deployment models. Through several case studies, Vipin and Sivaprasad underscore the importance of profiling applications on bare metal before deployment, using tools like flame graphs and perf, and understanding hardware details such as cache domains and PCI bus partitioning for optimization.
They call for enhanced telemetry and observability in DPDK for containerized environments, noting that current tools and documentation are inadequate for complex troubleshooting. Recommendations include extending DPDK’s telemetry infrastructure, utilizing eBPF hooks for improved runtime data collection, and ensuring consistent performance through better documentation, custom plugins for CPU isolation, and awareness of hardware-specific optimizations.
The presentation by Vivek Gupta delves into enhancing DPDK to facilitate the migration of various user space networking applications, pinpointing a critical issue: advancements in CPU, IO, and memory technologies are not benefiting these applications. Despite significant improvements in infrastructure, user space networking applications often fail to utilize these advancements effectively. This gap highlights the need for a framework that can bring the benefits of these technological improvements to user space frameworks, ensuring better performance and efficiency.
Customers face numerous challenges when attempting to migrate their existing user space applications to DPDK or VPP environments without rewriting them. These applications, which traditionally rely on Linux kernel methods, encounter significant hurdles during migration. The proposed solution is to create a unified framework that integrates various technologies, such as EF VI and VPP, to enhance the performance of these applications. This framework would support different levels of packet processing, from L2 to L4, and provide essential mechanisms for encryption, decryption, deep packet inspection, and proxy functions.
To meet customer needs, the framework should enable applications to capture and inject packets at various levels, from the interface to higher layers. It should support state management and route updates from control applications, ensuring that applications always operate with the most current data. Additionally, the framework must offer accelerators for cryptographic and AI/ML-based processing to handle the complex requirements of modern applications. By addressing issues related to threading, caching, and reducing contention, the framework aims to significantly improve the performance of user space applications.
Practical examples underscore the potential benefits of this framework. For instance, enhancing web servers, proxy servers, and video streaming applications using the proposed framework could lead to substantial performance gains. By tackling issues such as blocking operations and optimizing thread management, applications can achieve higher throughput and better resource utilization. The framework should also cater to the needs of high-speed applications and support flexible application architectures, enabling user space applications to become more efficient and faster.
In conclusion, the proposed enhancements to DPDK aim to bridge the gap between advancements in infrastructure and the performance of user space networking applications. By providing a comprehensive framework that supports various processing levels, state management, and cryptographic acceleration, the solution promises to improve application performance, reduce contention, and enhance resource utilization. This approach will help customers migrate their applications more effectively and realize the full benefits of technological advancements in CPU, IO, and memory technologies.
The Asia Pacific (APAC) region, particularly India and China, has established a strong and dynamic community around the Data Plane Development Kit (DPDK). Recognizing this, the decision was made to hold the DPDK APAC Summit in Thailand, a geopolitically neutral location that facilitates easy participation from various APAC countries without visa complications.
The DPDK project is witnessing robust growth in multiple areas, including technical contributions, marketing outreach, and the number of active contributors. This growth is further bolstered by increasing interest from new prospective corporate members, indicating a healthy and expanding ecosystem.
Significant updates have been made to the University of New Hampshire (UNH) lab, which has recently incorporated the Marvell CN10K Data Processing Unit (DPU) into its testing suite. The lab now reports Data Test Suite (DTS) results for a variety of tests, and has established a community dashboard for code coverage, releasing monthly reports. Additionally, the lab has been proactive in submitting patches and bug fixes and is running compilation tests for Open vSwitch (OVS) with each DPDK patch, with future plans to include performance testing.
Marketing efforts for DPDK have seen a considerable boost, with increased engagement on platforms like LinkedIn and a notable rise in YouTube views, which is seen as a leading indicator of the project’s growing interest. The steady increase in DPDK downloads further underscores the project’s rising popularity.
Enhancements to the DPDK documentation have also been a focal point, with updates to the Poll Mode Driver (PMD) guidelines, security protocol documentation, and multiple sections of the programmer’s guide and contributor guidelines. Financially, the DPDK project is in a strong position with a healthy budget and substantial reserves. This financial stability ensures that key activities such as summits, community labs, and marketing efforts are well-supported for the foreseeable future.
Sachin Saxena and Apeksha Gupta from NXP presented on integrating Eventdev with Traffic Metering and Policing to enhance Quality of Service (QoS). They discussed the various requirements from customers and the comprehensive solution they developed to meet these demands. Their goal was to share their extensive work and experiences with the community, offering insights into how similar challenges can be addressed effectively.
They highlighted different customer requirements, such as the need for traffic classification and scheduling in hardware, reducing CPU cycle usage, and implementing custom schedulers. By leveraging the DPDK framework, they managed to consolidate these varied needs into a generic solution. This approach not only met the specific requirements but also provided a reference for others in the community who might face similar challenges.
The technical approach of their solution involved utilizing DPDK’s metering, policing, and Eventdev frameworks. They explained how these components interact to meet the specified use cases, enhancing overall efficiency and performance. By breaking down complex use cases into manageable components and mapping these to corresponding RT library elements, they ensured a robust end-to-end functionality.
In their implementation details, they described the method of segmenting use cases into multiple components and aligning these with the appropriate RT library components. This strategy ensured that each part of the system worked seamlessly together, achieving the desired outcomes effectively and efficiently.
To illustrate their points, they shared practical use cases, including the management of scheduling priorities, grouping multiple ports, and applying markers and policers at the priority group level. These examples demonstrated how to optimize CPU cycles and prevent data loss, showcasing the practical applications of their solution in real-world scenarios.
Kumara Parameshwaran Rathinavel from Microsoft has been working on enhancing the Generic Receive Offload (GRO) library. GRO is a widely used software technique that optimizes packet processing by merging multiple TCP segments into a single large segment. Kumara has been contributing to this project since his time at VMware and continues to do so at Microsoft. His work aims to improve the efficiency and performance of GRO, particularly in the context of network traffic handling.
The current implementation of GRO, which involves iteratively checking a table for flow matches, has been identified as suboptimal for handling packets received in multiple bursts. This method can lead to inefficiencies, especially as the timeout intervals increase. Kumara highlighted that the existing approach struggles with scalability and performance under these conditions, necessitating a more efficient solution.
To address these limitations, Kumara proposed a hash-based method for flow matching. This new approach significantly enhances the efficiency of the GRO process. In tests, the hash-based method demonstrated substantial performance improvements, reducing the CPU utilization of the GRO reassemble function. This method not only optimizes the flow matching process but also ensures better handling of packet bursts, leading to overall improved performance.
Recognizing the varying latency requirements of different applications, Kumara suggested implementing tuple-specific timeouts within the GRO framework. This approach allows for more flexible and optimized GRO settings tailored to the specific needs of various applications. For instance, applications with low latency requirements, such as banking transactions, can have shorter timeouts, while those with less stringent latency needs can benefit from longer timeouts. This customization ensures that all applications can operate efficiently without compromising on performance.
To validate these enhancements, Kumara used a setup involving a virtual machine as a test proxy, demonstrating notable performance gains. The improvements in GRO are particularly beneficial for network applications like load balancers, where reducing CPU utilization and improving packet processing efficiency are critical. Kumara’s work on GRO library enhancements showcases significant advancements in optimizing network traffic handling, contributing to more efficient and scalable network performance.
The presentation focuses on the critical need for improved power management and efficiency for Telco operators, emphasizing the importance of vendor-agnostic solutions for scalability across different platforms. This is particularly relevant as power has become a significant concern, with the need to optimize performance per watt and manage power effectively.
AMD’s power library within the DPDK (Data Plane Development Kit) aims to address these concerns by balancing power consumption and performance. The library optimizes core and uncore frequency management and introduces adaptive algorithms for real-time monitoring and idle state management. This ensures that while cores are busy polling, they consume power efficiently without compromising on performance.
Currently, the power library is tightly coupled with Linux and requires specific modifications to accommodate new drivers, leading to inefficiencies and increased code size. Each new driver introduction necessitates changes to the core library, increasing the complexity and effort required for maintenance and updates. This approach is not scalable as the number of drivers and their capabilities grow.
To address these challenges, the refactoring efforts aim to modularize the power library, enabling plug-and-play capabilities for new drivers and reducing dependencies. This modular approach will simplify the addition of new drivers, improve performance, and enhance scalability by minimizing the library’s footprint and code complexity.
The proposed enhancements include vendor-agnostic uncore APIs to manage interconnect bus frequencies and dynamic link width management. These APIs promote a standardized interface for power management across different hardware vendors, making it easier for applications to develop power management solutions without being tied to specific vendors. This approach not only reduces complexity but also ensures compatibility and scalability across various platforms.
The Technical Board (TBoard) and Governing Board (GBoard) of the project play distinct but complementary roles in steering the community. The TBoard consists of 11 members who meet bi-weekly to discuss and resolve technical issues. These meetings, conducted via Zoom, involve all community members and focus on consensus-driven decision-making. When consensus cannot be reached, the TBoard votes on issues, requiring prior email submissions for agenda inclusion. This structured approach ensures thorough consideration and discussion before decisions are made.
The GBoard, on the other hand, sets the project’s broad direction, encompassing administrative tasks, marketing strategies, and budgeting. This board meets monthly and includes a permanent chairperson along with representatives from the Linux Foundation. The GBoard comprises 12 members: 10 from golden member companies, one from a silver member, and one from the TBoard. Every six weeks, the GBoard convenes, and every three months, they hold joint meetings with the TBoard to align on financial plans, marketing efforts, and major project decisions.
Membership in the GBoard is tiered, with gold members contributing $50,000 annually and silver members contributing $10,000 annually. These funds are crucial for project initiatives, such as summits and acquiring new servers for the lab. Gold members play a significant role in decision-making due to their financial contributions, ensuring their interests and investments are aligned with project goals.
Community involvement is a cornerstone of both boards’ operations. TBoard meetings are open to all, fostering transparency and inclusivity in technical discussions. Issues are raised via email, ensuring that all voices can be heard. The GBoard, while more focused on strategic direction, includes representatives from various companies to bring diverse perspectives to the table. This collaborative approach allows for comprehensive planning and execution of project initiatives.
Currently, the boards are prioritizing several key areas: enhancing security protocols and documentation, improving continuous integration (CI) performance testing, and integrating more functional testing in the Data Plane Development Kit (DTS). Future plans include creating a performance dashboard and requiring contributors to add tests for new features. These efforts aim to maintain high standards of performance and security, ensuring the project’s robustness and reliability for all users.
The presentation introduces a new feature for rte_flow, which focuses on comparison operations to enhance the flexibility of flow rules. This feature allows for comparisons between fields or between a field and an immediate value, providing more dynamic and versatile rule configurations. The presenter assumes familiarity with rte_flow from previous sessions and emphasizes the advantages of this new capability.
Traditional rte_flow rules are limited to matching immediate values, which can be restrictive in certain scenarios. For instance, in TCP connection tracking, the termination of connections often goes unnoticed by software if the reset packet is handled by hardware directly. Similarly, for packet payload evaluation, users may want to skip cryptographic operations on packets without payloads. These examples highlight the need for more advanced comparison methods in flow rules.
The new feature supports a range of comparison operations, including greater than, less than, and equal comparisons. It has been initially implemented in ConnectX-7 and BlueField-3 NICs, specifically within the template API. However, there are limitations, such as the inability to mix comparison items with other items and restricted field support. The feature is designed to be flexible but currently has hardware constraints that limit its full potential.
Users can configure these comparison rules using a new `item compare` structure in the API. This involves specifying the fields to compare, the immediate values, and the desired operations, such as equal, not equal, greater than, and so forth. The configuration also supports specific bit-width comparisons, providing detailed control over how comparisons are executed. This structure aims to offer a robust framework for implementing dynamic and complex flow rules.
Several examples demonstrate the use of the new comparison item in flow rules, illustrating its practical application. Despite its benefits, the feature currently supports only single comparison rules within flow tables and a limited range of fields. The requirement for both spec and mask in the configuration is due to the template API structure, which mandates these elements even if they might not be necessary for all comparisons. Suanming Mou concludes by encouraging other developers to integrate support for this feature in their PMDs, recognizing its potential to significantly enhance rte_flow’s capabilities.
The DPDK PMD live upgrade process is designed to meet the critical need for upgrading or downgrading PMD versions seamlessly without disrupting ongoing services. This process ensures the transfer of user configurations while minimizing downtime to nearly zero, making it essential for applications requiring continuous operation.
Two primary approaches are detailed for conducting these upgrades. The first approach involves a graceful exit of the old PMD followed by the restart of the new PMD, during which there is a brief period of service unavailability. The second approach utilizes a standby mode, where the new PMD is prepared with the necessary configurations but remains inactive until the old PMD exits. This method ensures that there is no service disruption as the traffic seamlessly switches to the new PMD once the old one exits.
To facilitate this process, two modes are introduced: active and standby. In the active mode, the PMD manages traffic and hardware configuration directly. In standby mode, configurations are set up but do not affect traffic immediately. Instead, they become active only when the old PMD gracefully exits, ensuring that the traffic handling transitions smoothly without any interruption.
A crucial aspect of the upgrade process is the use of group zero as a dispatcher for traffic processing rules. This mechanism ensures that all configurations are synchronized and become effective immediately, eliminating any downtime or disruption in traffic flow. By inserting and managing these rules efficiently, the system can transition from the old PMD to the new one seamlessly.
Finally, the process is designed to be highly scalable, allowing for adaptable resource usage to accommodate various deployment scales. It also emphasizes the importance of a user-friendly API, ensuring that users can access and utilize the upgrade features quickly and easily, thus enhancing the overall efficiency and effectiveness of the live upgrade process.
David Vodák from Cesnet presented their journey to enable 400G traffic monitoring using DPDK and FPGA-based SmartNICs, a project initiated due to the lack of suitable FPGA cards in the market. Cesnet, a national research and educational network, designed the FPGA SmartNIC which utilizes the Intel HX I7 chip with 400G Ethernet support and PCIe gen 4/5 compatibility. This card is engineered for high-speed processing, making it ideal for their needs.
The cornerstone of their solution is the NDK platform, an open-source framework that supports up to 400G throughput. NDK facilitates parallel processing, filtering, and metadata export, which are crucial for handling high-speed network traffic. It is designed to be highly adaptable, allowing users to create new components or use existing ones to build custom firmware for various applications.
NDK’s versatility extends beyond monitoring; it is also used for high-frequency trading and CL testing. One of the open source tools developed by Cesnet, the IPFIXPROBE, supports DPDK and is employed to create detailed traffic flows from input packets. This probe exemplifies the practical applications of NDK in real-world scenarios, demonstrating its robustness and flexibility.
To ensure the reliability of their solutions, Cesnet employs rigorous testing and verification methods. Functional testing is conducted using tools like testpmd or custom DPDK applications in loopback setups. For benchmarking, they utilize external traffic generators such as Spent and Flow Test, with the latter capable of simulating realistic network traffic to provide more accurate testing results.
Looking ahead, Cesnet plans to expand the capabilities of the NDK platform to support various cards and use cases beyond traffic monitoring. Their commitment to open source development is evident, as they provide extensive resources on GitHub for the community to collaborate and innovate further. This open source approach not only fosters community involvement but also drives continuous improvement and adaptation of their technology.
AMD undertook a project to repurpose its QDMA NIC for Forward Error Correction (FEC) offloading in virtual RAN environments using an FPGA-based prototype. The goal was to support LDPC encode/decode functionalities without developing the BBDEV PMD from scratch. Instead, the team adapted existing QDMA NIC code, incorporating necessary modifications to create a functional BB PMD. This approach allowed for rapid prototyping and integration within a short time frame.
Throughout the project, several challenges arose, including mismatched use cases, software latencies, and inadequate thread handling. To address these, the team implemented solutions such as using selective builds and applying compiler pragmas. These strategies helped optimize the RX/TX burst functionalities and reduce instruction cache misses, which in turn minimized overall latency.
Significant efforts were made to reduce latencies, which were initially high due to multiple factors including software and PMD-related overheads. By minimizing instruction cache misses and optimizing critical functions to fit within smaller memory pages, the team achieved notable latency reductions. Further improvements were realized by implementing lockless mechanisms using RT rings, ensuring efficient NQ/DQ operations.
To meet the specific requirements of the customer for low-latency and high-throughput, the team had to go beyond simple test scenarios and adapt the software implementations to better match real-world use cases. This involved modifying the BBDEV PMD to handle multiple threads and ensuring proper mapping and distribution of LDPC encode and decode requests, which significantly improved performance and reliability.
The project highlighted several important lessons. It underscored the value of reusing existing PMDs when feasible, as well as the need to reduce code bloating and align PMD examples with actual customer use cases. The team recommended updates for the DPDK community to focus more on low latency and stress testing, and to improve lockless implementations. These insights and improvements contributed to a more robust and efficient solution, ultimately enhancing the overall performance of the system.
The DPDK conference in Bangkok marked a significant milestone as the first APAC event since COVID-19. With a total of 63 participants, including 30 in person and 33 online, the event exceeded expectations. This conference, considered an experiment in a geopolitically neutral location, was deemed successful and has paved the way for potential future APAC events in various locations.
DPDK, a project now 14 years old, has shown remarkable growth and resilience, countering previous perceptions of being in its sunset phase. Since Nathan joined the Linux Foundation in April 2022, the project has maintained nearly perfect member retention and continued technological advancement. This longevity and sustained momentum underscore the project’s vitality and relevance in the tech community.
Strategic efforts in marketing and documentation have significantly enhanced the project’s visibility and usability. Under the direction of Ben Thomas, marketing initiatives have been robust, and tech writer Nini Purad has overhauled the project’s documentation. These efforts aim to foster community growth and engagement, ensuring that DPDK remains a valuable resource for its users.
The DPDK project is evolving in critical areas such as security, cloud hyperscaling, and AI. This evolution is driven by community input and the guidance of the tech board, including leaders like Thomas Monjalon. Continuous community involvement is essential for future advancements, highlighting the importance of active participation from all stakeholders.
Nathan emphasized the importance of community engagement in driving DPDK’s development forward. He encouraged attendees to participate through Slack, tech board calls, and contributions to the OSS code. Additionally, the project is actively creating dynamic content, including end-user stories and developer spotlights, to promote mutual growth and expand the membership base. This focus on community and content creation is key to sustaining and growing the DPDK project.
Watch all the summit videos here.