Navigating the Data Plane Development Kit (DPDK) release landscape requires a thorough understanding of what a Long-Term Stable (LTS) release entails and why it may be the preferred choice for certain network environments. This guide dives into the nuances of DPDK LTS, its suitability for production, and the level of active support it receives.
Understanding DPDK Long Term Stable (LTS) Releases
DPDK LTS releases stand out in the networking world for their reliability over an extended period. Here’s what sets them apart:
Longevity of Support: DPDK LTS offers a commitment of three years’ worth of fixes, ensuring that a chosen release remains robust against issues found long after its initial deployment.
Consistent Improvements: A DPDK LTS release isn’t static. It evolves with a series of API/ABI compatible drop-in replacements that incorporate the latest fixes discovered in the subsequent years. For instance, a series based on a 2022 DPDK release will be refined with fixes identified during 2023-2025.
Sustainability: This approach guarantees that production environments can rely on a consistent, stable platform without the need to constantly adapt to new feature changes.
DPDK LTS releases are tailored for specific scenarios within the networking domain
Ideal for Production: LTS releases are the go-to for production environments where stability is paramount and the latest features are less of a priority.
Focus on Stability Over Novelty: Organizations that value long-term reliability over cutting-edge features will find DPDK LTS releases more suitable.
Active Maintenance and Support
The vibrancy of the DPDK LTS ecosystem is reflected in the following statistics:
Multiple Active Releases: As of now, three LTS releases are being actively maintained: 21.11, 22.11, and 23.11.
Frequent Updates: 2023 saw 9 releases across these maintained LTS versions.
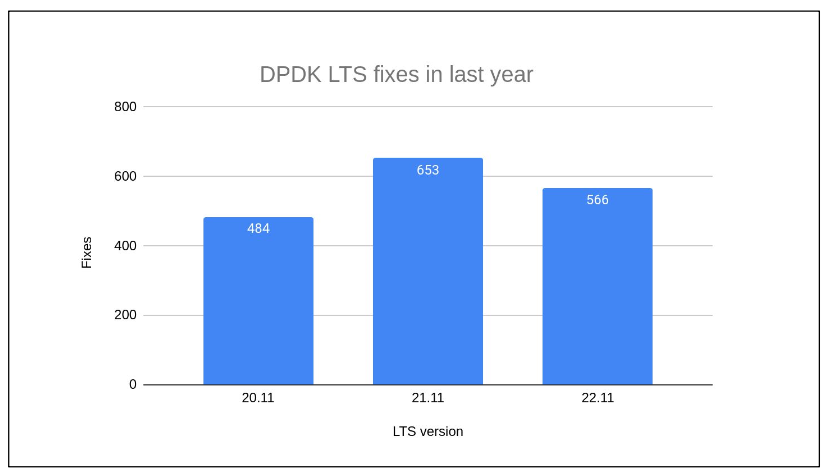
Volume of Fixes: Approximately 1800 fixes have been backported to the active DPDK LTS releases in the last year alone.
Maintenance Span for DPDK LTS
The commitment to maintain a DPDK LTS release is clear and long-term:
General Fixes: All identified fixes will be backported to the LTS releases for a full three years from their release date.
Security Patches: Security-related updates may even extend beyond the three-year window, ensuring that LTS releases maintain a strong defense against vulnerabilities.
Choosing a DPDK LTS Release
When deciding on a DPDK LTS release, consider the following:
Maintenance Timeline: Evaluate whether longer support windows aligns with your deployment cycle and update capacity.
Active Maintenance Record: The volume and frequency of backported fixes provide an indication of the LTS version’s vitality and the community’s dedication to its upkeep.
Security Commitment: With a promise of three-plus years of security fixes, assess whether this meets your organization’s security and compliance requirements.
Preparing for DPDK LTS Deployment
Transitioning to or between DPDK LTS releases requires an organization to:
Stay Informed: Keep abreast of the DPDK LTS release and maintenance schedules to time updates strategically.
Test Thoroughly: Allocate resources for detailed testing to ensure the LTS version integrates seamlessly with your environment.
Anticipate Adjustments: Be prepared for any necessary changes that might arise from the introduction of backported fixes.
Conclusion
Selecting a DPDK LTS release is a strategic decision influenced by the need for stability, long-term support, and a maintenance schedule that ensures network applications remain secure and performant.
With the extended support and backporting of fixes, DPDK LTS releases offer a dependable foundation for organizations seeking a stable networking stack. This maintenance model continues to be a cornerstone of network reliability, allowing organizations to leverage stable and secure networking functions without the churn of constant feature updates.
Authors: Ben Thomas (Linux Foundation Marketing Lead) & Kevin Traynor (LTS Maintainer & Software Engineer @ Redhat)
Navigating the complex landscape of Data Plane Development Kit (DPDK) releases, particularly Long-Term Support (LTS) versions, is often accompanied with pressing questions: “Which release is most suitable for my needs?” “What are the advantages of choosing an LTS release?” “How does an LTS release impact the stability and life span of my network applications?”
This detailed blog aims to shed light on these queries and steer you towards the appropriate DPDK LTS release for your specific requirements.
Understanding DPDK LTS Releases
DPDK is a collection of libraries and drivers that enable rapid packet processing, which is essential in network functions virtualization (NFV), cloud computing, and other high-speed networking environments.
LTS releases are special in that they are designated to receive ongoing maintenance updates, including bug fixes and security patches, for a longer duration than standard releases.
DPDK LTS vs. Standard Releases
DPDK standard releases are known for their rapid development and inclusion of bleeding-edge features. In contrast, LTS releases follow a more systematic and stable approach, focusing on a consistent cadence of fixes and releases.
This distinction is important for organizations deciding between adopting the latest DPDK features or prioritizing long-term stability, who anticipate a solid three-year cycle of maintenance, with security patches often exceeding this period.
Volume of Fixes in Each Release
A notable characteristic of DPDK LTS releases is the substantial number of fixes each version receives. This high volume of fixes is a testament to the active maintenance and commitment to ensuring the reliability and stability of each LTS version. It indicates the ongoing effort to address a wide range of issues, from minor bugs to critical vulnerabilities.
Simultaneous Maintenance of Multiple Versions
DPDK’s maintenance strategy includes managing three LTS versions simultaneously. This approach ensures that organizations using different versions of DPDK LTS receive the necessary support and updates. It exemplifies the dedication of the DPDK community to cater to a diverse range of users and their varying adoption timelines.
Differences in Fixes Across Versions
The number of fixes in LTS releases varies based on the age and lifecycle of the release. For instance, an older release like 20.11 tends to have fewer fixes as it matures and stabilizes over time. In contrast, a newer release like 22.11, which was released late in 2022, has not yet completed a full year of fixes. This discrepancy in the number of fixes reflects the evolving nature of each release and the continuous effort to enhance stability and performance.
Impact of Release Timelines on Maintenance
The timing of a release plays a critical role in its maintenance cycle. A newer release like 22.11, having been in the market for a shorter duration, might not have accumulated as many fixes as an older release. This variation underscores the importance of understanding the release timelines and their implications on the maintenance and support cycles of DPDK LTS releases.
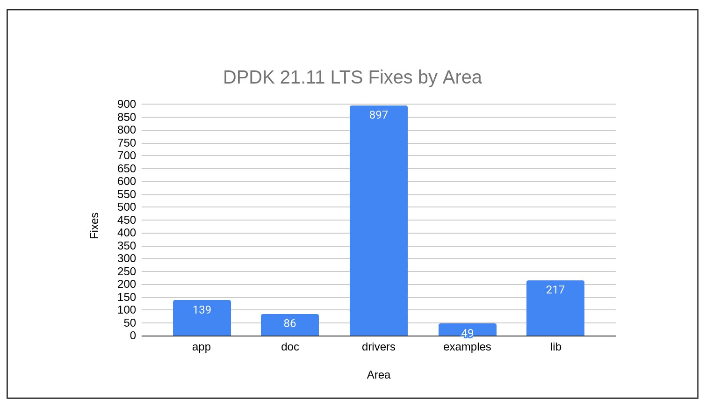
Enhanced Focus on NIC and Driver Fixes in LTS Releases
One of the key aspects of DPDK LTS releases is their focus on Network Interface Controller (NIC) and driver fixes. Hardware vendors are deeply invested in driver functionality, making them some of the most active contributors to the DPDK LTS ecosystem. Their involvement is crucial, as they provide the expertise and timely updates necessary to keep the drivers—and thus the network—running smoothly.
Trends in Bug Fixes and Maintenance
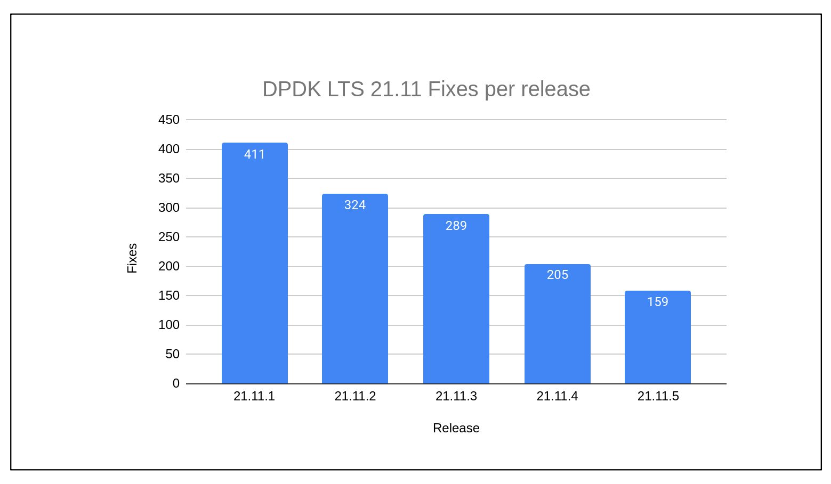
An analysis of recent LTS versions, such as version 22.11.3, reveals a trend of decreasing bug fixes. This trend corresponds to the number of bugs found in the main branch, contrasting with previous versions where fixes averaged around 300. The rate of fixes is not fixed; as a release ages, the number of fixes tends to decrease, indicating increased stability over time.
Longevity of LTS Maintenance
The question of why LTS releases are not maintained for extended periods, like 20 years, is addressed by the trend of diminishing fixes over time. As LTS versions become more stable, the need for frequent fixes decreases, justifying the typical LTS support duration.
Future Code Integrations and Impact on LTS
Looking ahead, future code integrations in DPDK may not significantly impact LTS releases. While library fixes might increase, the core stability of LTS releases is expected to be maintained.
The Process Behind DPDK LTS Releases
The philosophy guiding LTS maintenance encapsulates a straightforward principle: “Don’t make it worse.” Key aspects of this philosophy include:
LTS Selection: Annually, one DPDK release is chosen to become an LTS version. Typically this is the November DPDK release. This release ceases to receive new features but is maintained to address critical issues.
Maintenance Workflow: Fixes from subsequent releases are ported back to the LTS release. For instance, if a significant bug is fixed in a March release, that fix is usually also applied to the LTS version.
Vendor Contributions: Updates for drivers specific to various hardware vendors are included in LTS releases, ensuring that common components remain stable across different platforms.
Validation: LTS releases are validated through a mix of CI and vendors dedicating validation resources.
Distribution Adoption: Prominent Linux distributions such as Red Hat, Ubuntu and Debian favor LTS releases due to their longer support window and relative feature stability.
The Role of LTS in Upstream Maintenance
The DPDK upstream maintainers are committed to ensuring that LTS releases receive the necessary fixes without introducing new issues. This careful balance underscores their dedication to the core LTS premise.
Statistical analysis of LTS releases provides insight into several key areas:
Fixes: The quantity and significance of the bug fixes an LTS release receives.
Bug Age: The duration that bugs existed before being fixed, indicating the codebase’s stability.
Code Areas: The sections of code that were most frequently fixed, highlighting areas of potential vulnerability or critical importance.
Why Opt for DPDK LTS?
Opting for a DPDK LTS release over a standard one is akin to choosing a well-established airline for travel—while it may not boast the newest features, its track record for safety is impeccable.
Industry Adoption
Companies like Red Hat and Ubuntu use LTS releases because they trust the extended support period will provide a stable foundation for their network infrastructure. This trust stems from the methodical maintenance and broad community endorsement of LTS releases, which adds another layer of testing and quality assurance.
Community and Self-Support
While LTS releases are backed by community support, there is nothing to prevent organizations from taking on their support initiatives. For example, if a company needs to support a particular network card with custom features, they can take an LTS release and integrate their changes while still benefiting from the core stability that LTS provides.
Update Overhead
LTS offers flexibility of when to update to the next LTS. If a new feature of interest is available in the next LTS then it can be worth the effort to update and also extend the longevity of using a maintained release.
If not, then it is fine to skip and wait for a later LTS. Staying with an LTS series means less effort to get fixes. It also means API/ABI compatibility, so there are no application code changes needed and less frequent product integration testing.
What if there’s a new interesting feature that is not yet in an LTS release yet? With one LTS released per year, there is always another one coming soon.
Example Integration into Other Projects
Open source projects like Open vSwitch (OVS) integrate DPDK LTS to enhance their performance. Each year the OVS project takes the newest DPDK LTS and integrates into their next release. This means that OVS users benefit from fixes and stability in the underlying DPDK drivers that it uses.
Which LTS Release Should You Pick?
The choice of the right DPDK LTS release hinges on various factors:
Support Window: Assess the duration of support your deployment requires.
Feature Set: Determine whether the LTS release contains the necessary features for your network applications, keeping in mind that it takes time for new features to become stable.
Vendor Compatibility: Check if the LTS release supports your hardware and if vendor-specific drivers are maintained.
Preparing for Transition: From LTS to LTS
Transitioning from one LTS release to the next requires careful planning. As exemplified by maintainers like Kevin Traynor in the 21.11 release, the process is detailed but manageable. Organizations should:
Dedicate time to comprehensive testing when updating versions.
Anticipate and prepare to address possible integration issues.
The Future of DPDK LTS Releases
Looking forward, DPDK LTS releases will continue to be a cornerstone for networks that value stability. The DPDK community, in conjunction with hardware vendors, is committed to ensuring that LTS releases are equipped to handle the demands of modern networking environments.
As we navigate this terrain, the feedback loop between users and maintainers will remain vital. Each fix, each update, and each LTS release is a product of collective effort and shared knowledge.
Call to Action: Join the Effort
As the DPDK LTS ecosystem thrives, we extend an open invitation to more companies and contributors to provide their input and expertise. Whether you’re a hardware vendor with an eye on driver optimizations or an enterprise leveraging DPDK for high-performance networking, your experiences and contributions are invaluable. The strength of an LTS release is not just in its code—it’s in the community that molds and shapes it.
The DPDK Summit 2023 was a showcase of technical breakthroughs and forward-looking discussions in the field of high-performance networking. The summit featured a range of presentations, each diving into new developments and future directions. Here are the highlights from the key talks.
Rashid commenced with a nod to the global audience, addressing the challenges and breakthroughs in DPDK’s trajectory. He extended his gratitude toward the contributions made by the DPDK Board of Governors, the project’s contributors, and the sponsors who fuel the initiative’s progress.
Intel’s Cristian Dumitrescu and Radu Nicolau presented a method to boost P4 software pipelines using standalone software modules called extern blocks. Focusing on IPsec, they demonstrated how to employ DPDK libraries to add acceleration to P4 pipelines, enabling them to handle IPsec processing in parallel with regular pipeline functions. The IPsec block, working as an accelerator, is seamlessly integrated using packet queues and supports multiple security protocols without needing changes to the P4 pipeline code.
Sean Cummings and Chris Cummings from ESnet discussed the use of DPDK as an offload engine for P4 SmartNIC applications. They highlighted how DPDK can manage complex packet translations that P4 cannot, using their experience with a SIIT-DC NAT64 translator on FPGAs as a case study.
David Marchand from Red Hat analyzed tc-flower and rte_flow, two frameworks used for offloading complex packet processing to NICs within OVS. He provided insights into the performance and integration status of rte_flow compared to tc-flower.
Christophe Fontaine from Red Hat presented the application of rte_flow to virtual interfaces, explaining the benefits and the performance gains achievable, which elevate virtio’s capabilities from 4Mpps to line-rate.
Maxime Coquelin from Red Hat compared the performance of VDUSE with other solutions like Vhost-user and VETH pairs in conjunction with Virtio-vDPA, building upon the previous year’s introduction to VDUSE’s architecture.
Kiran KN and Shailender Sharma from Juniper Networks introduced a cloud-native virtual DPDK Cell Site Router (vCSR) designed for the 5G ORAN ecosystem. They detailed its architecture, integration with Juniper’s control plane, and its role in enhancing connectivity in a disaggregated RAN setup.
Elena Agostini and Gal Cohen from NVIDIA spoke about accelerating 5G RAN and UPF. Elena focused on the NVIDIA Aerial SDK’s use of DPDK for building a 5G software stack, while Gal discussed the benefits of using SmartNICs and DPUs for UPF, highlighting the scalability and performance enhancements provided by DPDK.
Ferruh Yigit from AMD provided a thorough explanation of ABI versioning in DPDK. He discussed the application of ABI versioning, a topic that has seen limited use and understanding, offering a step-by-step guide and examples for its implementation in DPDK.
Aaron Conole’s session revolved around the evolution of CI pipelines within the DPDK ecosystem. He took the audience through a brief history of CI infrastructure development and outlined the current landscape. The crux of his talk was the envisioned transformation of the CI pipeline into a decisive factor for patch acceptance.
This talk addresses the challenges in high-performance packet processing when multiple DPDK processes need to work cooperatively. Normally, splitting a workload across independent processes involves standard inter-process communication (IPC) methods that can be inefficient, as they usually require multiple data copies and complex descriptor manipulations.
Zhifei Yang presented an intriguing session on integrating DPDK with Confidential Virtual Machines, a critical aspect of cloud security. He emphasized how cutting-edge technologies like AMD SEV, Intel TDX, and ARM CCA are empowering users to deploy services in the cloud without fully trusting the cloud provider. Yang pinpointed the unique challenges of running high-performance DPDK applications within CVMs, from the need for shared hugepages to the current suboptimal state of DPDK’s memory management in such environments.
Chenbo Xia and Yahui Cao from Intel led the conversation with an introduction to the integration of new VFIO and IOMMU frameworks within DPDK. The implementation of IOMMUFD in the Linux Kernel calls for DPDK’s alignment to utilize features like PASID/SSID and DMA Page Fault handling. The new VFIO Chardev framework also opens doors to more efficient VFIO device management, promising to refine DPDK’s hardware interactions.
Ruifeng Wang of Arm China talked about the integration of the Arm64 Scalable Vector Extension (SVE) into the DPDK libraries. This integration promises to enhance computational efficiency for network tasks on Arm architectures, leveraging the SIMD feature.
Vivek Gupta from Benison Technologies shared insights into the complexities encountered in the development of various DPDK-based applications. He stressed the need for standard solutions that could ease the process of developing and migrating applications to DPDK.
Harry van Haaren from Intel suggested leveraging Rust for DPDK functionalities to combine performance with safety. The use of Rust aims to prevent API misuse and provide an easier configuration experience.
Ajit Khaparde of Broadcom discussed improving the RAS features in DPDK by involving applications in the error recovery process. Such involvement is crucial for ensuring systems remain robust and reliable.
William Lam from TikTok introduced Bytebricks, a graph library-powered VPN framework that leverages DPDK for superior performance. The framework shows how to manage timers in a scalable way across multiple cores, with a focus on the implementation of the Wireguard protocol.
Intel’s Leyi Rong talked about sketch-based algorithms in DPDK for network telemetry, which are essential for detecting large network flows while being memory-efficient and computationally effective.
Jerin Jacob from Marvell provided a detailed overview of the DPDK graph library’s design and implementation, a feature that has enhanced DPDK’s data processing capabilities since its release.
Sivaprasad Tummala from AMD addressed the performance challenges faced with DPDK’s distribution packaging, which must cater to various CPU architectures, often at the cost of optimal performance.
Lastly, Jianzhang Peng from Timeresearch showcased dperf, a network load tester based on DPDK that significantly outperforms traditional testing methods in performance, convenience, and cost.
The DTS Working Group update was an opportunity to understand the work that had been accomplished, the challenges that had been faced, and what lay ahead. Honnappa Nagarahalli, Juraj Linkes, and Patrick Robb discussed the tangible outcomes of their collaborations, the intricacies of their current projects, and provided a roadmap for future releases. Their talk delved into technical details and discussed how the group’s work aligned with the broader goals of DPDK.
Tobias Roeder’s presentation on DPI-enhanced DPDK threw a spotlight on the intersection of DPDK and 5G technologies. He delved into how deep packet inspection (DPI) could augment DPDK’s capabilities, particularly for the user plane in 5G networks. He talked about the successful application cases, performance benchmarks, and how the integration of DPI with DPDK features like rte_flow and RSS was contributing to the 5G revolution. His presentation rounded out with practical insights from deployments and simulations that mirrored current 5G user behaviors, providing attendees with a grounded perspective on the technology’s current and future impacts.
As the summit came to a close, it was essential to reflect on the wealth of knowledge and innovations that had been shared. Thomas Monjalon, a seasoned DPDK maintainer from NVIDIA, concluded the event with his remarks. He recapped the summit’s highlights, underscored the importance of the community’s contributions, and charted the course for the future development of DPDK. He focused on the collaborative spirit that has been a hallmark of DPDK’s success and acknowledged the emerging trends and technologies that would shape its evolution.
The open-source community thrives on collective efforts to improve and augment software products. In this post, we take a closer look at the operations of the Data Plane Development Kit (DPDK) community lab and its contributions towards testing and refining the DPDK software project.
DPDK, a set of libraries and drivers for fast packet processing, is embraced by major technology players including Red Hat, NVIDIA, Intel, Arm, and more. However, a crucial element that bolsters the confidence of these companies in DPDK is the dedicated testing Community Lab hosted by the University of New Hampshire Interoperability Lab. Their primary service to the DPDK community involves rigorous testing of code contributions and providing valuable feedback to the developers.
The DPDK Community Lab: An Overview
Initiated around 2017-2018, the DPDK Community Lab was conceived to ensure that incoming code contributions didn’t introduce performance regressions across various vendor channels. Initial testing focused primarily on performance testing and gradually expanded to encompass a broader range of checks.
The lab executes multiple categories of tests on incoming source code contributions, including performance, functional testing, unit and compile testing, and Application Binary Interface (ABI) stability checks. ABI testing provides stability for development across different versions within that cycle. For instance, releases 22.11, 23.03, and 23.07 are/will be ABI compliant with the current major abi version. A new major ABI version will be released with the 23.11 LTS release which may break ABI compliance with releases from the current cycle. But then the subsequent 24.03 and 24.07 releases will be ABI compliant to the ABI major version introduced at 23.11.
The Testing Suite: A Developer’s First Encounter
One of the first steps for developers contributing to DPDK involves navigating the project’s mailing list, where they submit patches for review. Any code change or patch is subsequently passed through the community lab’s testing suite. Should a patch trigger an issue or fail the automated tests, the developers are notified through email as well as the ‘patchwork’ system, an automated web portal that tracks incoming source code patches.
Understanding the testing suite is an essential part of a new developer’s journey. Once developers familiarize themselves with the codebase, the next stage involves learning how to submit patches and navigate the unique mailing list patch archive approach, which can initially be somewhat alien to developers more accustomed to using the major code collaboration and version control tools like GitLab, GitHub, or Bitbucket’s direct patch submission process.
Extending Test Coverage: Evolution Over Time
Over the years, the DPDK community lab has significantly extended its test coverage, adding new types of hardware, architectures, and operating systems to its testing suite. In 2022 and 2023 the Community Lab has worked to update our internal container build system to make it OCI compliant. That has allowed the lab to seamlessly offer the same test coverage for arm64 platforms which was previously offered only for x86 systems. The lab has also made other expansions for ARM, like adding arm32 unit tests to CI runs, and is proud to say there is now parity between x86 and ARM test coverage in the Community Lab.
The lab operates on the principle of relative comparison; it does not publish absolute performance numbers. Instead, it compares the performance of a patch against the mainline version of the codebase. This approach ensures that no individual patch introduces significant performance degradation, which could negatively impact end users and integrators.
Policies and Test Cases
The lab derives its test cases from several sources, primarily the DPDK core developer community and the DPDK Test Suite (DTS). The latter focuses on functional testing and performance testing of the DPDK system as a whole, while the former is focused on individual building blocks within the codebase. There’s an ongoing effort within the community to merge DTS into the DPDK main repository to align its release cycles more closely with those of DPDK itself.
The third category of tests comes from purpose-built sample applications, such as the Federal Information Processing Standards (FIPS) test cases. These cases test the implementation of cryptographic algorithms built into DPDK. With recent advancements from NIST, the lab has transitioned from a manual vector request and testing approach to an automated API-driven process, which greatly facilitates the automation of cryptographic implementation testing.
Testing Methods
At the heart of the lab’s testing approach are three key methods: unit testing, functional testing, and performance testing. Each of these contributes a different perspective, ensuring a comprehensive review of the application. For instance, unit testing focuses on the smallest parts of the application, while functional and performance testing assess the application’s functionality and speed under various conditions.
Compiling is an important step in the process, which they undertake before running ABI (Application Binary Interface) tests. Ensuring that the interface remains consistent is vital, as it confirms the binary formatting of the interfaces isn’t altered. This ensures that applications depending on the DPDK stack don’t face unexpected failures.
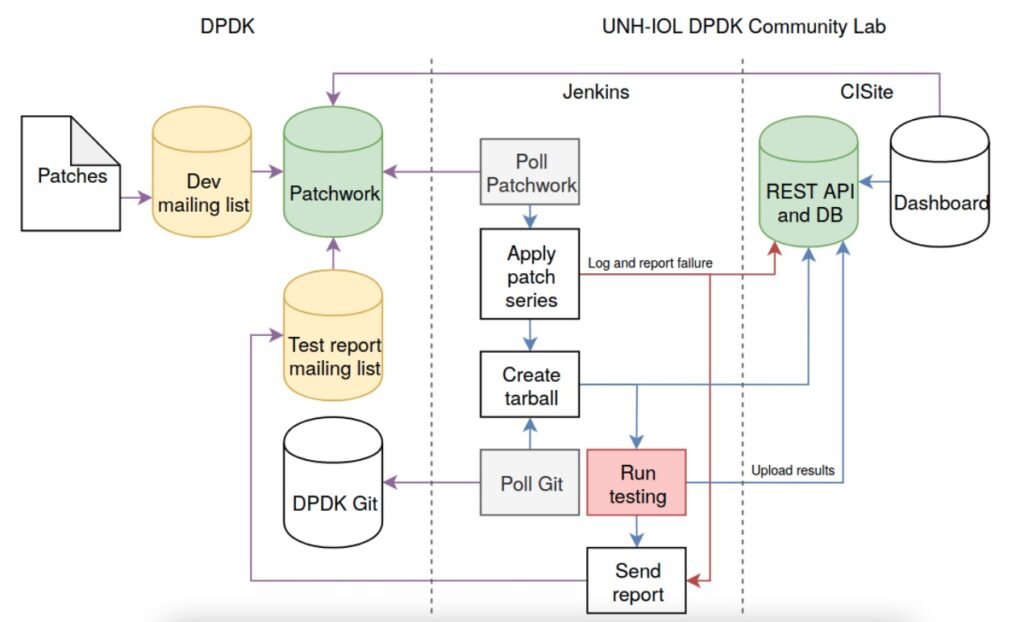
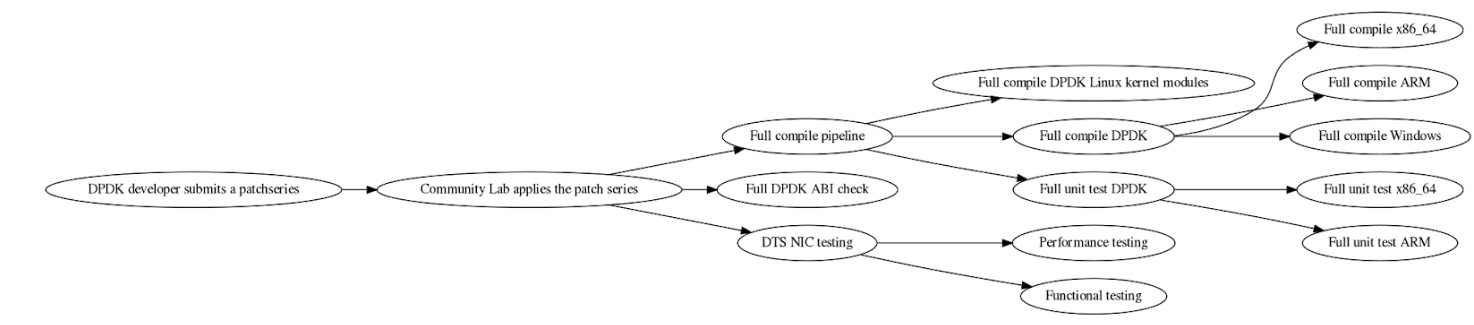
The lab’s Continuous Integration (CI) platform, Jenkins, is instrumental in organizing the testing workflow. A graphical representation of our Jenkins Testing Tree can offer a clearer understanding of the testing process, starting from patch application, branching into various forms of testing, and then cycling back for reiteration.
As patches flow into the system, Jenkins starts the process by applying these patches to the DPDK Mainline. If the patches apply correctly, the updated DPDK enters the testing pipeline. The system then breaks down into functional and performance testing using the DPDK Test Suite (DTS) across different servers and network interface cards (NICs). Concurrently, ABI testing ensures consistency at the driver kernel level. Simultaneously, they conduct compile testing on both x86 and ARM architectures. Finally, DPDK’s inbuilt unit tests confirm the robustness of each small part of the software.
Expanding Partner Coverage
In terms of expanding the lab’s test coverage and partnering with member companies, they have historically relied on organic growth within the community. However, recent efforts have focused on DPDK Gold members, targeting the integration of their latest generation hardware into the Lab’s testing suite. This direct engagement ensures their systems are among the first tested by DPDK’s community infrastructure, providing a clear benefit for their participation.
The DPDK Community lab does not eliminate the need for in-house testing, instead it complements it, providing an additional layer of assurance and reliability. Being an open-source project, the lab’s testing capabilities offer wide-ranging coverage, ensuring that the project is robust and dependable. The ongoing expansion of the lab test coverage is testament to the DPDK community’s commitment to delivering consistently robust code.
We’re excited to share with you the news that a new major release, DPDK 23.07, is now available for download. Here, we will take a detailed look at what this release brings to the table, the contributors behind it, and what lies ahead for the DPDK community.
Unpacking DPDK 23.07
Despite the overall number of commits being modest at 1028, this release signifies a considerable amount of work as indicated by the number of changed lines: 1554 files were altered with 157260 insertions and 58411 deletions. This endeavor was not a small feat as it involved 178 authors who each put their expertise and dedication into making this release possible.
Community Engagement and Contributions
Our doors are always open for more hands, and we encourage anyone willing to contribute in various stages of the process. There is a wide array of areas you can help in, such as testing, review, or merge tasks. Every contribution, no matter how small, brings us one step closer to our common goal.
It’s worth noting that there is no plan to start a maintenance branch for 23.07. However, this new version is ABI-compatible with 22.11 and 23.03, which means it will interact seamlessly with the binaries built with these older versions.
Notable New Features in DPDK 23.07
The new release brings forth several enhancements and features, promising an improved experience for users.
Some of these additions include the AMD CDX bus, PCI MMIO read/write capabilities.
It includes new flow patterns (Tx queue, Infiniband BTH), new flow actions (push/remove IPv6 extension) and also introduces an indirect flow rule list.
As well as a vhost interrupt callback, more ShangMi crypto algorithms, and a PDCP library.
We have also seen the removal of the LiquidIO driver, a move that aligns with the DPDK’s commitment to providing a refined and optimized toolkit.
Finally, this release includes a DMA device performance test application and there are some progress with the new DTS: it is able to run a basic UDP test now, improving utilities for developers.
More details about these changes can be found in the release notes here.
A Big Welcome to New Contributors
The DPDK community is growing, and 23.07 has seen contributions from 37 new contributors including authors, reviewers, and testers. We extend our warm welcome to all of them and appreciate their invaluable contributions.
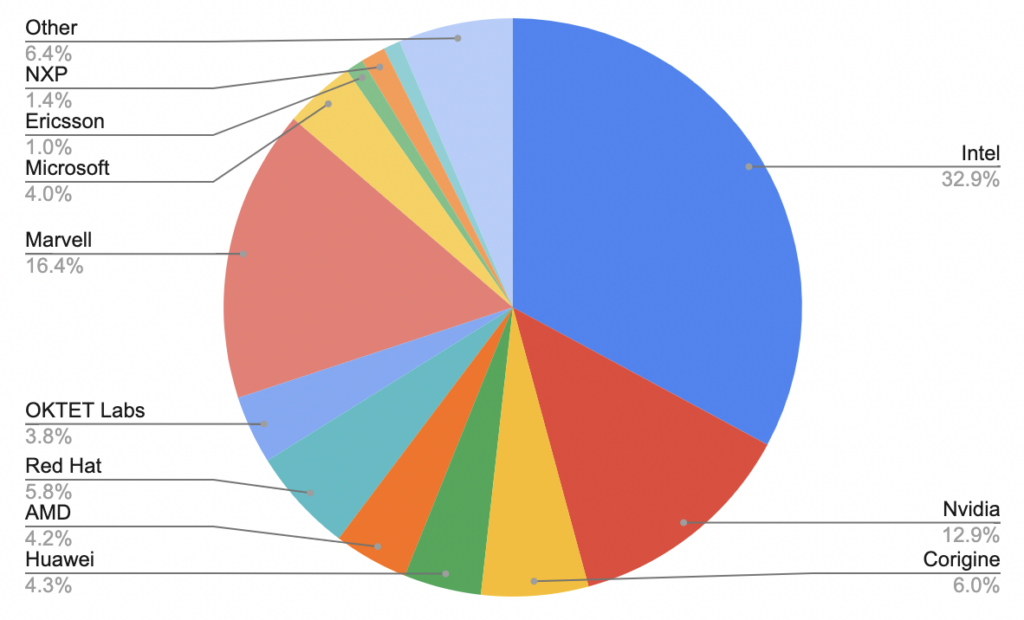
DPDK 23.07 was not a solo effort. The release has seen contributions from multiple organizations, the leading contributors being:
Intel (252 commits), Marvell (225 commits), and NVIDIA (127 commits), among others. This community effort underlines the collaborative spirit of the DPDK project.
Reviewer Acknowledgements
A special thank you goes to all those who took up the often under appreciated task of reviewing other peoples work. Your efforts have been instrumental in maintaining the high quality of DPDK code. The top non-PMD reviewers, based on Reviewed-by and Acked-by tags, include Ferruh Yigit, Akhil Goyal, David Marchand, Chenbo Xia, and Bruce Richardson.
Looking Ahead
However, there is always room for improvement. There are currently more than 300 open bugs in our Bugzilla, and the number of comments in half-done work (like TODO, FIXME) is on the rise. This highlights a need for increased efforts in code cleanup.
Looking to the future, the next version, 23.11, is slated for release in November. We encourage developers to submit new features for this version within the next two weeks. You can find the next milestones here.
Mark Your Calendars
Lastly, don’t forget to register for the upcoming DPDK Summit in September. It’s a great opportunity to connect with the DPDK community, learn about the latest developments, and share your experiences.
A big thank you to everyone for your continuous contributions to DPDK. See you in Dublin for the DPDK Summit!
Hosted by The University of New Hampshire InterOperability Lab (UNH-IOL), the DPDK Community Lab exists to provide prompt and reliable continuous integration(CI) testing for all new patches submitted to DPDK by its community of developers. Every time a patch is submitted to DPDK Patchwork, it is automatically applied to the main DPDK branch, or the appropriate next- branch, and run across our test beds. Now entering its 6th year in operation, the Community Lab has progressed beyond its initial goal of simply providing performance testing results. Test coverage is also provided for functional, unit, compile, and ABI testing across a wide array of environments. This has brought greater development stability and feedback to the DPDK developer community, and also to DPDK gold project members who are eligible to host their resources (NICs, CPUs, etc.) at the UNH-IOL lab. This is a great value provided not only to DPDK at large, but also to the participating vendors who would otherwise have to host this testing in house at a significant cost or develop their products without the reliable and timely feedback that CI testing provides.
In 2022, the Community Lab again expanded on its existing operations. Members of the Community Lab submitted patches to DPDK and DTS in order to increase testing and demonstrate DPDK functions. This year, we also broadened the reach of our testing on a hardware coverage level and test case level. With new Arm servers, updated NICs from our participating members, and our furthered use of containerization, we have greatly diversified the set of environments under testing. Specific examples of developments and happenings in the Community Lab this year include, but are not limited to, the following:
Submitted patches to DPDK in order to bring its FIPS compliance and FIPS sample application up to date with new processes from NIST, and set up CI infrastructure to test and demonstrate these capabilities across crypto-devs and algorithms.
Expanded hardware testing coverage by introducing newer, higher capacity NICs, as well as expanded our test coverage on ARM based systems.
Expanded DPDK branch coverage, including the new LTS “staging” branches. By incorporating these branches into the CI testing process, we can provide greater stability for LTS backporting.
Participated in the DPDK Test Suite (DTS) working group to develop the new DTS and incorporate it into the DPDK main repository. Our contributions included collecting feedback from the community to determine requirements for DTS, setting new formatting standards and development best practices to provide high quality code, and developing a testing approach that provides a consistent environment between users by containerizing DTS.
Developed and upstreamed a container building system to the DPDK-CI repository.
Updated our Linux distribution test coverage list based on community feedback.
Worked with Microsoft to bring DPDK unit testing to Windows.
Made the necessary changes in our internal infrastructure and in DPDK to enable OpenSSL unit testing in the lab.
We’re proud of the work we’ve done at the DPDK Community Lab, and we’re looking forward to the 2023 goals. We will work to maintain the test coverage we’ve built up over years and push to demonstrate and test more features according to the desires of the community and our participating vendors. On the hardware side, we aim to introduce new NICs for testing, and incorporate other types of hardware accelerators where possible. Ideally, we will also partner with more DPDK gold member companies to provide our CI testing on their platforms and equipment. Another goal is to expand our traffic generator options so we can provide testing on a broader range of environments. On the software side, the Community Lab will continue making contributions toward the development of new DTS, implementing an email based retesting framework, and increasing our contributions and involvement with the DPDK continuous integration repo. We want to strengthen CI testing within our own lab, but also across the entire community. We’re going to continue engaging with the DPDK CI community, and as always, anyone interested in our work or CI testing in general can find us bi-weekly at the DPDK Community CI meetings. We look forward to writing another blog post in one year’s time to review and reflect on the progress made in the lab during the 2023 calendar year!
There are 74 new contributors (including authors, reviewers and testers).
Welcome to: Abdullah Sevincer, Abhishek Maheshwari, Alan Liu, Aleksandr Miloshenko, Alex Vesker, Alexander Chernavin, Allen Hubbe, Amit Prakash Shukla, Anatolii Gerasymenko, Arkadiusz Kubalewski, Arshdeep Kaur, Benjamin Le Berre, Bhagyada Modali, David MacDougal, Dawid Zielinski, Dexia Li, Dukai Yuan, Erez Shitrit, Fei Qin, Frank Du, Gal Shalom, Grzegorz Siwik, Hamdan Igbaria, Hamza Khan, Henning Schild, Huang Wei, Huzaifa Rahman, James Hershaw, Jeremy Spewock, Jin Ling, Joey Xing, Jun Qiu, Kaiwen Deng, Karen Sornek, Ke Xu, Kevin O’Sullivan, Lei Cai, Lei Ji, Leszek Zygo, Long Wu, Lukasz Czapnik, Lukasz Kupczak, Mah Yock Gen, Mandal Purna Chandra, Mao YingMing, Marcin Szycik, Michael Savisko, Min Zhou, Mingjin Ye, Mingshan Zhang, Mário Kuka, Piotr Gardocki, Qingmin Liu, R Mohamed Shah, Roman Storozhenko, Sathesh Edara, Sergey Temerkhanov, Shiqi Liu, Stephen Coleman, Steven Zou, Sunil Uttarwar, Sunyang Wu, Sylvia Grundwürmer, Tadhg Kearney, Taekyung Kim, Taripin Samuel, Tomasz Jonak, Tomasz Zawadzki, Tsotne Chakhvadze, Usman Tanveer, Wiktor Pilarczyk, Yaqi Tang, Yi Li and Zhangfei Gao.
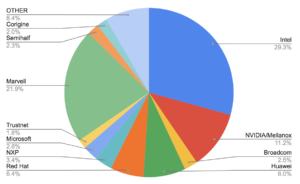
Below is the number of commits per employer:
A big thank to all courageous people who took on the non rewarding task of reviewing others’ work! Based on Reviewed-by and Acked-by tags, the top non-PMD reviewers are:
(53) Akhil Goyal
(45) Andrew Rybchenko
(36) Morten Brørup
(34) Niklas Söderlund
(34) Bruce Richardson
(33) David Marchand
(31) Ori Kam
(25) Maxime Coquelin
(21) Jerin Jacob
(20) Chengwen Feng
The next version, DPDK 23.03, will be available in March of 2023. The new features for 23.03 can be submitted during the next 4 weeks: http://core.dpdk.org/roadmap#dates
Note: GCC 12 may emit some warnings, some fixes are missing.
Welcome! There are 44 new contributors (including authors, reviewers and testers):
Abdullah Ömer Yamaç, Abhimanyu Saini, Bassam Zaid AlKilani, Damodharam Ammepalli, Deepak Khandelwal, Diana Wang, Don Wallwork, Duncan Bellamy, Ferdinand Thiessen, Fidaullah Noonari, Frank Zhao, Hanumanth Pothula, Heinrich Schuchardt, Hernan Vargas, Jakub Wysocki, Jin Liu, Jiri Slaby, Ke Zhang, Kent Wires, Marcin Danilewicz, Michael Rossberg, Michal Mazurek, Mike Pattrick, Mingxia Liu, Niklas Söderlund, Omar Awaysa, Peng Zhang, Quentin Armitage, Richard Donkin, Romain Delhomel, Sam Grove, Spike Du, Subendu Santra, Tianhao Chai, Veerasenareddy Burru, Walter Heymans, Weiyuan Li, Wenjing Qiao, Xiangjun Meng, Xu Ting, Yinjun Zhang, Yong Xu, Zhichao Zeng and Zhipeng Lu.
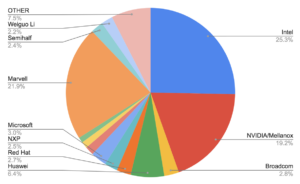
Below is the percentage of commits per employer:
A big thank to all courageous people who took on the non rewarding task of reviewing others’ work. Based on Reviewed-by and Acked-by tags, the top non-PMD reviewers are:
54 Akhil Goyal 52 Fan Zhang 42 Jerin Jacob 35 Chenbo Xia 34 Maxime Coquelin 28 Andrew Rybchenko 23 Matan Azrad 21 Bruce Richardson 20 Qi Zhang 20 Ferruh Yigit 19 Morten Brørup 19 Anoob Joseph
The Next version, 22.11, is scheduled for release in in November, 2022. New features for 22.11 can be submitted during the next 4 weeks: http://core.dpdk.org/roadmap#dates Please share your roadmap.
There are 51 new contributors (including authors, reviewers and testers)!
Welcome to Abhimanyu Saini, Adham Masarwah, Asaf Ravid, Bin Zheng, Brian Dooley, Brick Yang, Bruce Merry, Christophe Fontaine, Chuanshe Zhang, Dawid Gorecki, Daxue Gao, Geoffrey Le Gourriérec, Gerry Gribbon, Harold Huang, Harshad Narayane, Igor Chauskin, Jakub Poczatek, Jeff Daly, Jie Hai, Josh Soref, Kamalakannan R, Karl Bonde Torp, Kevin Liu, Kumara Parameshwaran, Madhuker Mythri, Markus Theil, Martijn Bakker, Maxime Gouin, Megha Ajmera, Michael Barker, Michal Wilczynski, Nan Zhou, Nobuhiro Miki, Padraig Connolly, Peng Yu, Peng Zhang, Qiao Liu, Rahul Bhansali, Stephen Douthit, Tianli Lai, Tudor Brindus, Usama Arif, Wang Yunjian, Weiguo Li, Wenxiang Qian, Wenxuan Wu, Yajun Wu, Yiding Zhou, Yingya Han, Yu Wenjun and Yuan Wang.
Below is the percentage of commits per employer (with authors count):
A big thank to all courageous people who took on the non rewarding task of reviewing others’ work.
Based on Reviewed-by and Acked-by tags, the top non-PMD reviewers are: 41 Akhil Goyal 29 Bruce Richardson 26 Ferruh Yigit 20 Ori Kam 19 David Marchand 16 Tyler Retzlaff 15 Viacheslav Ovsiienko 15 Morten Brørup 15 Chenbo Xia 14 Stephen Hemminger 14 Jerin Jacob 12 Dmitry Kozlyuk 11 Ruifeng Wang 11 Maxime Coquelin
The next version of DPDK, 22.07, will be released in July.