

By Honnappa Nagarahalli
DPDK is widely used across the technology industry to accelerate packet processing on a varied mix of platforms and architectures. However, all architectures are not created the same way and they all have differing characteristics. For frameworks such as DPDK, it is a challenge to efficiently use specific architecture features without impacting performance of other supported architectures.
One such characteristic is the memory model, which describes the behavior of accesses to shared memory by multi-processor systems. The Arm and PowerPC architectures support a weakly ordered memory model whereas x86 supports a strongly ordered memory model. Consider the following table that shows the ordering guarantees provided by these architectures for various sequences of memory operations.
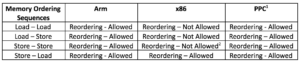
As shown above, in the Arm architecture, all four possibilities of sequences of memory operations can be reordered. If an algorithm requires these memory operations to be executed (completed) in the program order, memory barriers are required to enforce the ordering. On x86, only store – load sequence can be reordered and requires a barrier to enforce the program order. The other sequences are guaranteed to execute in the program order.
However, not all algorithms need the stronger ordering guarantees. For example, take the case of a simple spinlock protecting a critical section.
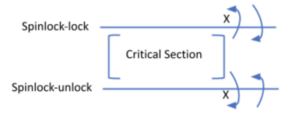
The operations inside the critical section are not allowed to hoist above ‘spinlock-lock’ and sink below ‘spinlock-unlock’. But the operations above are allowed to sink below ‘spinlock-lock’ and the operations below are allowed to hoist above ‘spinlock-unlock’. In this case, protecting the critical section using locks does not require that lock and unlock functions provide full barriers. This gives more flexibility to the CPU to execute the instructions efficiently during run time. Note that this is just one example and many other algorithms have similar behaviors. The Arm architecture ‘provides load/store instructions, atomic instructions and barriers that support sinking and hoisting of memory operations in one direction [3].
In order to support such architectural differences DPDK uses abstract APIs. The rte_smp_mb/wmb/rmb APIs provide support for full memory barrier, store memory barrier and load memory barrier. APIs for atomic operations such as rte_atomic_load/store/add/sub are also available. These APIs use full barriers and do not take any memory ordering parameter that help implement one-way barriers. Hence, it is not possible for the DPDK internal algorithms and applications to make use of the underlying CPU architecture effectively.
Exploring options
The DPDK community explored several options to solve this issue. The first option looked at relaxing the memory barriers used in the implementation of the above-mentioned APIs. It was soon realized that the type of memory ordering required depends on the algorithm and cannot be generalized. i.e., different algorithms may call the same API with different memory ordering. The second option looked at extending the existing APIs to take the memory ordering as one of the parameters while providing backward compatibility to existing APIs. This would however have resulted in writing large number of APIs to conform with the existing APIs.
Enter C11 Memory Model
The C language introduced the C11 memory model to address the above discussed differences in CPU architectures. It provides a memory model, that encompasses the behavior of widely used architectures, for multiple threads of execution to communicate with each other using shared memory. The C language supports this memory model through the atomic_xxx APIs provided in stdatomic.h. GCC and Clang compilers also provide __atomic_xxx built-ins. These APIs and built-ins allow the programmers to express the weak memory ordering inherent in their algorithms.
Several algorithms in DPDK were modified to use the C11 memory model on Arm. These changes didn’t affect the performance on x86 and at the same time, it improved the performance on weakly ordered memory model architectures like Arm. Thorough testing was done on several more algorithms to prove this further. Based on these results, the DPDK Tech Board voted unanimously to adopt the C11 memory model as the default memory model starting in the 20.08 release [4]. This means that, all the patches submitted by the DPDK community for subsequent releases should use C11 memory model. In order to support this adoption, Arm has agreed to change the existing code to use C11 memory model.
Community Discussions
The community discussed whether to use the __atomic_xxx built-ins or the atomic_xxx APIs provided via stdatomic.h. The __atomic_xxx built-ins require the memory order parameter in every built-in, requiring the programmer to make a conscious decision on the right memory order to use. They are supported by GCC, ICC and Clang compilers. The atomic_xxx APIs are not supported by compilers packaged with older versions of Linux distributions. After some debate it was decided to use the built-ins as there was no advantage in using the atomic APIs.
For x86 architecture, the __atomic_thread_fence(__ATOMIC_SEQ_CST) generates mfence instruction. DPDK implements the same barrier semantics with less overhead. Hence a decision was taken to introduce a wrapper rte_atomic_thread_fence. For x86 architecture, it calls the optimized implementation for __ATOMIC_SEQ_CST and calls __atomic_thread_fence for the rest. For rest of the architectures, it calls __atomic_thread_fence.
The community also decided to enforce this adoption using the check patch script. The script is updated to throw a warning if the patch uses the rte_smp_mb/rmb/wmb and rte_atomic_xxx APIs. All patch owners must fix such warning by using the __atomic_xxx built-ins. It is also the maintainers’ responsibility to look out for these warnings.
Current Status
Even though Arm has agreed to change the existing code to use C11 memory model, contributions from the community are highly welcome. So far 12 libraries have been updated with several more still to be updated. Several race conditions and atomicity related bugs have been identified and fixed during this process.
Conclusion
The adoption of the C11 memory model has helped DPDK community to develop robust code that performs best on all supported architectures. The community has developed a very good understanding of the C11 memory model.
If anyone needs help in designing/coding their next algorithm using C11 memory model, please ask at dev@dpdk.org.
Acknowledgements
Special thanks to Ola Liljedahl, Philippe Robin, Ananyev Konstantin, David Christensen and David Marchand for reviewing this blog.
References
[1] https://openpowerfoundation.org/?resource_lib=power-isa-version-3-0
[2] https://software.intel.com/content/www/us/en/develop/download/intel-64-and-ia-32-architectures-sdm-volume-3a-system-programming-guide-part-1.html
[3] https://developer.arm.com/documentation/100941/0100/
[4] https://mails.dpdk.org/archives/dev/2020-April/165143.html

