

The difference is DPDK (Data Plane Development Kit). Where every other partner uses dedicated silicon to meet the latency requirements of real-time sensor streaming, NXP runs a general-purpose applications processor…
Read More


TL;DR / Key Results
“DPDK let us look at the header while it was still in L3 and write the payload exactly where the GPU expects it.” — Andre Renard
We needed the cluster to ingest over 6.4 Tb/s without major CPU resources.
“Instruments break not with loud bangs but with slow math: a firehose of packets the CPU can’t place, ring buffers that miss by a cacheline, correlators that stall because a matrix never quite arrived in order.”
When the Canadian Hydrogen Intensity Mapping Experiment (CHIME) started seeing the sky as streams of UDP from thousands of digitizers, Andre Renard had one job that mattered: get every packet where the GPU expects it, on time, without roasting host memory bandwidth.
CHIME’s design bet early on GPUs for correlation, cheap FLOPs, tensor cores on the horizon, rapid iteration. That created a different bottleneck: host memory. Traditional paths (kernel sockets, two-pass reorders, GPU-side reshuffles) burned cycles and DRAM bandwidth they didn’t have. Renard’s team started looking at DPDK.
The move was pragmatic. Poll-mode to avoid context switches; DDIO to inspect headers while the bytes are still in LLC; non-temporal writes to land payloads directly at precomputed strides. One pass across cache, one write to DRAM, one GPU read.
Andre Renard (University of Toronto / CHIME Collaboration) joined CHIME as project staff: a computer scientist embedded in a physicist-led experiment. “It’s definitely not a solo project,” he says. Multiple institutions, from UBC to Perimeter to McGill, share software development; 5-10 engineers contribute at any time across telescopes. Renard took the network path: FPGAs push UDP; GPUs correlate; the host makes it look easy.
“I’m proud we made the world’s largest radio correlator of its time actually work, bandwidth, antennas, the whole thing, and that our piece of the pipeline held up.”
By the time CHIME began building, GPUs for radio astronomy had moved from a curiosity to a credible option. FPGAs and ASICs still dominated the front end, but matrix-heavy, low-bit-depth math made GPUs attractive and cost-effective. CHIME’s architecture took advantage of that:
The catch was scale. The project moved UDP Packets at over 6.4 Tb/s across point-to-point links from F engines to X-engine GPU nodes. The canonical approaches in similar systems—split headers/payloads with verbs, land payloads, then second-pass reorder on CPU or GPU—double-touch DRAM and overuse cores.
“We hit host memory bandwidth early. That was our wall, more than PCIe or GPU FLOPs.”
The idea that “the kernel can take it” was a non-starter. Even older CHIME nodes ran ~25.6 Gb/s per CPU, and upgrades now target ~100 Gb/s per NUMA. That mandates kernel bypass and ruthless avoidance of extra passes.
Make a UDP firehose look like a tidy, GPU-ready matrix without:
CHIME’s additional constraint: they maintain a RAM ring buffer of incoming baseband (raw) data. If an event (e.g., FRB) triggers, they pull the raw segment from RAM. SSDs can’t keep up (endurance and bandwidth), and spinning disks are out of the question at these rates. That rules out “NIC→GPU only” paths: the data must pass through host DRAM anyway.
“The dream of NIC DMA straight into GPU is nice, but our science needs a full-rate copy in host RAM.”
So the path had to both feed the GPU and preserve a DRAM copy, with minimal memory traffic.
The team leaned into three ideas:
This flips the usual reorder pattern. Instead of landing payloads “somewhere,” sorting later, and writing again, the RX path places each packet once where it belongs in the final GPU-consumable layout. Then the GPU reads once, and math begins.
“We can even scatter/gather: same packet payload written into multiple precomputed strides so the final matrix shape is perfect for the kernel.”
That last part matters in that correlation is outer products over many inputs and channels. Arranging memory in the right order translates directly into higher GPU occupancy and simpler kernels.
CHIME sits at the intersection of astronomy, HPC, and network systems. Each community brings different mental models:
CHIME’s software framework, Kodakan, bridges the gap. It hides DPDK boilerplate (NIC init, RX queue mapping, core pinning) behind base classes and YAML pipeline descriptions. Teams across instruments can implement a new “stage” without learning every DPDK nuance or pthread trick.
“One binary can run different telescopes by swapping the YAML pipeline. In some limited cases, you can build a new instrument mostly by writing a new config.”
At the packet path level:
Scope & limits (explicit):
Scope: Host-side packet → DRAM placement optimized for GPU consumption; baseband retention in RAM; portable across several telescopes via a shared framework.
Limits: UDP ingress expects packet order gaps; logic tolerates reordering but assumes very low loss; still host-DRAM mediated (no NIC→GPU direct placement), by design.
“Isn’t verbs/RDMA the modern way?”
Renard’s team considered verbs-based split and reorder. The challenge: extra passes. Either a CPU second pass to reorder or a GPU reorder that burns global memory and adds complexity. Their constraint, full-rate baseband in RAM, means NIC→GPU doesn’t remove the DRAM trip. DPDK minimizes it to one write.
“Poll-mode wastes cores.”
They run on 6-core CPUs in many nodes, intentionally small, because the CPU’s job is mostly copy/placement with few cycles per packet. DPDK’s low overhead made that feasible. On newer 100 Gb/s per NUMA nodes, they add distributor cores; the model still holds.
“Kernel bypass is dated; smart NICs can fix this.”
Smart NICs or programmable NIC pipelines could help, but economics and programmability matter. Commodity NICs plus DPDK delivered, repeatedly, across multiple instruments. The hardware dream Andre sketches, programmable on-NIC address calculation from custom headers, remains compelling if it arrives as a commodity surface.
“The bet is simple: one pass across cache, one write to DRAM, one GPU read. Anything extra pays interest in costs bandwidth you don’t have.”
Goal: Land UDP payloads into GPU-ready DRAM tiles in a single pass.
Environment (representative):
Build/Run sketch (framework-agnostic pseudocode):
// Pseudocode: single-pass placement
while (rx_dequeue(pkts, RX_BURST)) {
for (pkt in pkts) {
hdr = parse_header(pkt); // still in LLC via DDIO
// Compute one or more target offsets for scatter
for (t in layout_targets(hdr)) {
nt_store(t.dst, pkt->payload, t.len); // non-temporal write to DRAM
}
}
}
// GPU stage DMA-reads the arranged tiles and launches corr kernels.
Config checklist:
Sanity checks:
The correlator work sits alongside and in conversation with broader radio astronomy efforts, teams exploring NIC→GPU placement, terabit class ingress, and tensor-core-tailored kernels. Renard calls out ASTRON work (e.g., John Romein) exploring DPDK for GPU memory regions and extreme bandwidth. While CHIME’s current path stays DRAM-centric by design, these lines of work are converging on the same question: How do we feed accelerators at scale without melting host resources?
“Long term, everyone faces the same problem: feeding GPUs without burning CPUs or DRAM.”
Wishlist for NICs + APIs:
Onboarding path:
Project links:
Ask Renard what he’d change in DPDK, “It does what we need.” Then the engineer resurfaces: bulk enqueue semantics, on-NIC programmable address transforms, a commodity way for FPGAs to produce RDMA-placeable streams without heroic RTL. None of that contradicts CHIME’s DRAM-first reality. It simply opens options for the next instruments.
“I’d love a commodity NIC where I upload a tiny program: here’s my header, here’s the formula, put the packet exactly there.”
If you’re a developer who enjoys cachelines, NUMA maps, and the satisfaction of shaving one more pass off a hot path, CHIME’s approach shows the shape of the work: make placement decisions earlier; touch memory fewer times. Bring that energy to DPDK, to Kotekan, and to the telescopes that still need to be made real.
Get Involved: Review your first DPDK patch
The Canadian Hydrogen Intensity Mapping Experiment (CHIME) is a fixed, wide-field radio telescope located at the Dominion Radio Astrophysical Observatory near Penticton, British Columbia. It uses four stationary, 100-meter-long cylindrical reflectors in a drift-scan configuration: as Earth rotates, CHIME continuously maps a narrow north–south strip of the sky. Its science focuses on three pillars: 21-cm cosmology (tracing large-scale structure via neutral hydrogen and baryon acoustic oscillations), pulsar timing (including gravitational-wave–related studies), and fast radio bursts (FRBs), with outrigger stations added for high-precision FRB localization.
On the compute side, CHIME pairs FPGA “F-engine” front ends (digitization and channelization with a corner-turn) with GPU “X-engine” correlators that perform massive outer-product math to form visibilities and images. The collaboration spans multiple institutions—the Dominion Radio Astrophysical Observatory, McGill University, and many other institutions.—with shared software frameworks that enable related instruments (e.g., sister arrays in Canada and South Africa) to reuse pipeline components and configurations.
The Linux Foundation is the world’s leading home for collaboration on open source software, hardware, standards, and data. Linux Foundation projects, including Linux, Kubernetes, Model Context Protocol (MCP), OpenChain, OpenSearch, OpenSSF, OpenStack, PyTorch, Ray, RISC-V, SPDX and Zephyr, provide the foundation for global infrastructure. The Linux Foundation is focused on leveraging best practices and addressing the needs of contributors, users, and solution providers to create sustainable models for open collaboration. For more information, please visit us at linuxfoundation.org.
Last Updated: 03/19/2026

Tobias Roeder, Application Engineer at ipoque – a Rohde & Schwarz company, has spent years working at the intersection of deep packet inspection (DPI), open source packet processing, and telecom infrastructure. In a recent interview and follow-up to his DPDK Summit presentation, Tobias offered a candid view into how ipoque’s DPI engine integrates with DPDK rte_table API , and how their customer base, spanning startups to large telcos, leverages DPDK features to build intelligent, efficient, and secure networks.
ipoque provides a commercial DPI SDK that classifies traffic in real time without requiring decryption. It’s used to classify a wide variety of consumer and enterprise applications (e.g., WhatsApp, Netflix, MS Teams or VPN-Services) up to industrial IOT protocols (e.g. MQTT, Modbus, OPC UA..). The ultimate goal is to identify encrypted flows, and support decisions in firewalls, gateways, loadbalancers, UPFs, and other network functions.
While DPI isn’t new, its complexity has risen dramatically with the growth of encrypted and obfuscated protocols. As Tobias explains, “It used to be simple, most traffic was unencrypted or used more verbose TLS handshakes. Now, TLS 1.3 ESNI and QUIC obfuscation make traditional methods ineffective. Our DPI uses supervised machine learning to differentiate things like video-streaming versus video-downloading. ”
“It used to be simple, most traffic was unencrypted or used basic TLS. Now, TLS 1.3 and QUIC make traditional methods ineffective. Our DPI uses supervised machine learning to differentiate things like video-streaming vs video-downloading.”
For ipoque, DPDK serves as the abstraction layer that simplifies NIC access and enables rapid deployment across diverse environments, from embedded NXP devices to BlueField DPUs. “DPDK creates a very well-maintained base layer that abstracts away network card complexity,” Tobias notes. “It is our customers’ first choice of open-source packet processing frameworks.”
“DPDK creates a very well-maintained base layer that abstracts away network card complexity,” Tobias notes. “It is our customers’ first choice of open-source packet processing frameworks.”
Many of ipoque’s customers already have DPDK integrated into their stacks. Others migrate with Tobias’s team’s help. DPDK’s LTS stability and availability of tooling like testpmd are cited as core strengths in onboarding new users.
Two DPDK features stand out for ipoque’s use cases:
These libraries simplify otherwise complex aspects of connection tracking, which would need to be built and maintained independently.
While AI in packet processing is often discussed at the infrastructure level (CI systems, test automation, or inference at the edge), ipoque integrates supervised Machine Learning and Deep Learning algorithms directly into its SDK. This helps identify traffic types even when protocol handshakes offer no visibility.
For instance, distinguishing a user video-streaming from video-downloading (both encrypted) is no longer feasible through traditional methods “Enhancing DPDK QoS with DPI allows for video optimization in 4G/5G packet cores.” Tobias explains.
“Enhancing DPDK QoS with DPI allows for video optimization in 4G/5G packet cores.”
Tobias acknowledges the performance burden posed by encrypted traffic and evolving transport protocols like QUIC. Features like multiplexed streams over UDP present new challenges to fair scheduling in mobile networks. For this reason, DPI-enabled user plane functions (UPFs) benefit from accurate traffic classification within DPDK-forwarding paths.
Tobias’s insights also align with a wave of recent updates from the company:
When asked what excites him most about the future, Tobias points to cross-project collaboration and expanding DPDK’s reach beyond traditional telecom and networking. “It’s been amazing to see projects like radio telescopes and sensor analytics using DPDK. We’re eager to support use cases that aren’t just about routers, 4G/5G cores and firewalls.”
“It’s been amazing to see projects like radio telescopes and sensor analytics using DPDK. We’re eager to support use cases that aren’t just about routers, 4G/5G cores and firewalls.”
As protocols evolve and encryption deepens, DPI’s role becomes more nuanced. The toolkit must be accurate, passive, and fast, and the packet processing framework underneath must be efficient, adaptable, and stable.
For ipoque, DPDK is the first choice for user-space packet processing. And for the wider ecosystem, Tobias’s work highlights how DPI isn’t just surviving encryption, it’s evolving with it.

[img source p5. https://www.ipoque.com/media/brochures/Solution_guide_en_DPI_3608-7309-62_v0201_144dpi.pdf]
Learn More:

Kubernetes revolutionized application orchestration, but infrastructure management? Still a mess of REST APIs and shell scripts that barely integrate with the ecosystem. Guvenc Gulce and IronCore Team saw datacenter operators wrestling with networking solutions that treated Kubernetes as an afterthought, bolted on rather than built in.
The vision was clean: pure IPv6 underlay networks, software-defined overlays, SmartNIC offloading, all controlled through native Kubernetes APIs. No NAT boxes. No firewall appliances. Just L3 routing with SDN on top. One of the important challenges of this endeavor ? Building a dataplane fast enough to hit line-rate while maintaining the flexibility to integrate deeply with Kubernetes.
That’s where dpservice comes in – and where DPDK became essential.
“We thought that there was a need for a good solution for Kubernetes based infrastructure management for real and virtualized resources in a datacenter environment with software components designed from the beginning to integrate nicely with the Kubernetes ecosystem,” Güvenç explains.
That motivation drove the creation of dpservice as a key component of the SDN layer for IronCore – an open source, EU-funded project under The Linux Foundation and NeoNephos Foundation.
The problems in the open source infrastructure space were clear. “A lot of the infrastructure resource management projects were using REST APIs and/or script based solutions lacking operational logic and they would integrate half-heartedly with Kubernetes and they were not really designed with Kubernetes in mind,” Güvenç notes. These solutions treated Kubernetes as just another API endpoint rather than embracing it as the foundation for infrastructure orchestration.
The architectural vision went further.
“We also think that datacenter underlay traffic can be simple and only using IPv6 is enough. This would ease network operations and reduce the amount of used appliances in the datacenter. (NAT / Firewall boxes),” says Güvenç.
The idea: dpservice sitting on top of a simple IPv6 underlay network would offer software defined networking functionality by making use of SmartNICs, while IPv4 and IPv6 could still be offered in the customer virtual network.
This wasn’t about recreating existing virtual switches. It was about rethinking datacenter networking from first principles with Kubernetes as the control plane.
When you’re building high-performance SDN, your options narrow quickly.
“If you need fast / low latency / high throughput software defined networking in datacenters, you don’t have that many options. EBPF and DPDK are the first two dominant technologies that come to your mind,” Güvenç explains.
The team chose DPDK for specific reasons: “it offers a rich ecosystem of libraries to develop the dataplane/packet processing logic and offers a nice software abstraction to offload the traffic completely to the hardware.”
The performance target wasn’t ambitious – it was absolute.
“By using DPDK, we can reach line-rate in the software defined network functions we use which is actually the highest performance you can get.”
Line-rate means the theoretical maximum throughput of the hardware. There’s no performance left on the table.
This matters because dpservice isn’t handling toy workloads. It’s the SDN layer for production infrastructure supporting virtualized and bare metal resources. Packet forwarding, routing, NAT, firewalling – all happening in software at wire speed. DPDK’s library ecosystem made this achievable without writing everything from scratch.
The hardware offload abstraction proved equally critical. SmartNICs can take over packet processing tasks entirely, but only if the software can communicate with them effectively. DPDK provides that layer, letting dpservice treat hardware acceleration as a configuration choice rather than a complete architectural rewrite.
At its core, dpservice is a DPDK-based dataplane designed for a specific architectural vision. Unlike OVS-DPDK or VPP, it’s built around assumptions that simplify datacenter operations.
“OVS-DPDK and VPP are two prominent examples when it comes to DPDK based virtual switches and routers but they both also have their pros and cons and would not fit to our use-case 100%,” Güvenç explains. “OVS is very L2 oriented for example but our solution aims for simplifying the underlay network where we keep the L2 networks very small (2 members) and run the communication purely L3 based.”
VPP presented different challenges.
“VPP’s code is also mostly not based on DPDK libraries and has a steep learning curve, if you want to adapt it to your needs. DPDK is doing a much better job here and the VPP’s graph based dataplane approach can be used also in the DPDK ecosystem where dpservice is also doing it.”
The distinctive features emerge from these design choices. “The unique features of dpservice are being very L3 oriented, supporting IPv6 from the beginning, Supporting SR-IOV and hardware flow offloading from the beginning,” says Güvenç. The project also ships with “a kubernetes controller and API which can be used to create Virtual Networks, Virtual Interfaces and Network Functions.”
That Kubernetes integration isn’t an afterthought. The metalnet controller (https://github.com/ironcore-dev/metalnet) bridges dpservice into the broader IronCore ecosystem, making network resources manageable through standard Kubernetes patterns.
Güvenç’s own summary captures it well:
“dpservice project delivers a high-performance DPDK based dataplane for SR-IOV virtual functions, seamlessly integrating into Kubernetes environments through its metalnet controller to provide scalable software defined networking services.”
The push for Kubernetes-native infrastructure management isn’t about following trends. “Seamless Kubernetes integration is important as we think that Software Defined Networking should have all the positive effects of a Kubernetes based infrastructure management, like self-healing of managed systems and easier Day-2 operations with a better central insight to the managed systems underneath,” Güvenç explains.
For operators, the abstraction changes daily work. “For an operator, the managed virtual machines, metal machines and virtual networks are like abstract resources and he doesn’t need to deal with specific machines and customer networks in the infrastructure. These are declared as kubernetes specifications and they get materialized with Kubernetes controllers in place. Operator’s job can be simplified and automated.”
The benefits extend to AI-driven operations. “It would be even easier to inject AI based decisions into an IaaS system which uses Kubernetes as there are mature AI based decision helpers which nicely integrate with Kubernetes,” notes Güvenç.
Developers gain leverage too. “A developer can also rely on the battle-tested Kubernetes libraries / testing frameworks when he/she develops his/her resource management logic and this would make possible to concentrate on the real value delivered (like in our case an SDN layer) as the rest is already a mature technology which can be leveraged.”
The observability story integrates naturally. “We also use Prometheus and Grafana from CNCF project suite to give a better observability to dpservice internals. Prometheus exporters can nicely integrate with DPDK’s telemetry interface.” The entire cloud-native ecosystem becomes available once you’re Kubernetes-native.
dpservice doesn’t exist in isolation. It’s the SDN layer for IronCore, which tackles infrastructure-as-a-service challenges in the NeoNephos Foundation context. “IronCore is the project in Neonephos context which concentrates on infrastructure management. It is a typical IaaS project/offering and it is one of the important building blocks to provide the high level services in the sovereign cloud context, like platform mesh and it integrates nicely with other Neonephos projects like Gardener and Garden Linux.”
The European sovereign cloud effort addresses real concerns about infrastructure independence and data sovereignty. dpservice provides the high-performance networking layer that makes this vision technically feasible. “dpservice is providing the SDN layer of the IronCore IaaS and making it an important piece in the overall context.”
The project is young in the open source world. “The project is not so widely known yet as it was donated to The Linux Foundation only 3 months ago by SAP,” Güvenç notes. The contributor base reflects this early stage: “We have on our github page 14 contributors at the moment. I am the single maintainer and technical lead of the dpservice project at the moment but we have 3 more key people contributing to dpservice. The initiator of the project is Malte Janduda and the other two key contributors are Jaromír Smrček and Tao Li .”
The organizational backing is visible. “The organisations which are involved are also the same organisations which are members of the Neonephos Foundation. This can be seen publicly on the Neonephos page: https://neonephos.org/members“
The dpservice team is actively seeking connections with the broader DPDK community.
“We would be happy to get feedback about the dpservice project from the DPDK community,” says Güvenç.
“I am already in close contact with the maintainers and technical committee of the DPDK and presented dpservice to them. We also explore possibilities of what we can upstream from dpservice to the DPDK ecosystem. There are the first ideas emerging like re-usable DPDK Graph nodes which can be contributed to the DPDK community.”
This upstream engagement could benefit both projects. DPDK gains real-world validation of its graph-based dataplane approach and potentially reusable components. dpservice gains visibility and community feedback that can strengthen the project.
The roadmap is public and actively maintained: https://github.com/orgs/ironcore-dev/projects/13
Two major features dominate the near-term plan. “The most important two things we plan to do in the near future is to give the ability to dpservice encrypt the traffic leaving from it to the wire and decrypt the traffic it receives from the wire,” Güvenç explains. Wire-level encryption adds another layer of security for sovereign cloud deployments where data protection is paramount.
“The second important thing on the roadmap is to integrate High Availability to dpservice so that dpservice can run with two instances and there is the possibility of seamless failover from one instance to the other one.” Production infrastructure demands resilience, and HA support moves dpservice from interesting technology to production-grade component.
You don’t need a datacenter to experiment with dpservice. The team built ironcore-in-a-box specifically to lower the barrier to entry. “If someone wants to try dpservice or IronCore. You don’t need first a complex infrastructure for it. We have the ironcore-in-a-box project which uses the Kind cluster to demonstrate the usage of the IronCore project. TAP device based dpservice is included. Installation is very easy.” (https://github.com/ironcore-dev/ironcore-in-a-box)
For developers looking to contribute, Güvenç provides clear starting points. “For the potential contributors, I would recommend to start with the developer documentation of dpservice https://github.com/ironcore-dev/dpservice/tree/main/docs/development and for the overall understanding of IronCore, I would recommend to start with the IronCore documentation https://ironcore.dev/iaas/getting-started.html and especially networking part of it.”
A technical deep dive is available for those who want more detail: https://guvenc.github.io/software%20engineering/2024/10/18/dpservice.html
The project welcomes engagement. “We also welcome contributions / comments and more stars for the GitHub page of the dpservice.” (https://github.com/ironcore-dev/dpservice)
Building infrastructure software can be thankless work – months of effort invisible to end users. But Güvenç finds motivation in real-world impact. “I think the most exciting and rewarding moment is to see other people use dpservice / IronCore and they can get an added value out of it.”
The development experience itself offered early wins. “During the build phase it was very exciting to make fast progress to implement the first features of dpservice as the DPDK has nice examples and a wide range of libraries which make the first success moments quickly possible.”
That’s DPDK’s strength showing through – not just raw performance, but an ecosystem that accelerates development. When your networking dataplane needs to hit line-rate while integrating with Kubernetes, talk to hardware SmartNICs, and support production workloads, you need a foundation that handles the complexity. DPDK provides that foundation.
dpservice shows what becomes possible when you build on it.
Try dpservice:
Connect with the team on Linkedin:

Introduction:
How does a developer go from a fascination with programming to creating a leading open source project that reshapes network performance testing? Jianzhang Peng’s story begins as a developer working on L4 load balancers, using DPDK to tackle the complex challenges of modern networking. He created DPERF, a high-performance load testing tool, to address gaps in existing solutions and share it with the open source community. His journey into open source and the DPDK ecosystem is one of passion, persistence, and innovation.
When asked about the beginning of his programming journey, Jianzhang reflects: “I started programming during my university days, about 20 years ago. Initially, it was a skill I developed through academic study, but it soon became a career that allowed me to solve real-world problems.”
His career began at a startup, where he worked on both L4 and L7 load balancers before joining Baidu Cloud as a developer specializing in L4 load balancing. It was during his time at Baidu Cloud that Jianzhang encountered the limitations of commercial testing tools. “We were using a commercial tester, but the performance just wasn’t good enough,” he recalls. “I decided to write a testing tool myself, initially for personal use. Over time, I realized it could benefit others as well, so I decided to open source it.”
“We were using a commercial tester, but the performance just wasn’t good enough,” he recalls. “I decided to write a testing tool myself, initially for personal use. Over time, I realized it could benefit others as well, so I decided to open source it.
From Commercial Tools to Open Source
At Baidu Cloud, Jianzhang’s primary focus was on developing L4 load balancers. These systems manage huge amounts of traffic by distributing client requests across thousands of backend servers. “A lot of clients send requests to the L4 load balancer,” he explains, “which holds the public IP address, processes the incoming connections, and schedules them to the backend servers. The workload is immense, requiring highly optimized solutions.”
“A lot of clients send requests to the L4 load balancer, which holds the public IP address, processes the incoming connections, and schedules them to the backend servers. The workload is immense, requiring highly optimized solutions.”
While working on these load balancers, Jianzhang’s team relied on commercial testing tools to evaluate performance. However, these tools were not portable and struggled to meet the high-performance demands of L4 load balancers. Frustrated by these limitations, Jianzhang decided to create a solution tailored to his needs. The result was DPERF, a tool designed to provide high-performance, portable, and efficient testing specifically for L4 load balancers.
Joining the DPDK Community
Jianzhang’s introduction to DPDK came while working on Baidu Cloud’s load balancers, many of which were powered by DPDK. This open source framework enables developers to build fast, efficient packet processing applications. Recognizing the synergy between DPDK and his project, Jianzhang leveraged its capabilities to enhance DPERF’s performance. “We used DPDK for L4 load balancing,” he notes. “Its performance was a key factor in the success of our systems.”
“We used DPDK for L4 load balancing,” he notes. “Its performance was a key factor in the success of our systems.”
The Beginnings of DPERF
While working at Baidu, Jianzhang encountered significant challenges with the commercial testing tools available at the time. “The performance of these tools was not good enough,” he recalls. “They were designed as physical devices that had to be installed in a data center, which made them difficult to use in distributed or remote environments.” This limitation inspired Jianzhang to create a new solution.
“The performance of these tools was not good enough,” he recalls. “They were designed as physical devices that had to be installed in a data center, which made them difficult to use in distributed or remote environments.”
“I found that most open source testers were focused on Layer 7 (L7) testing, but the performance wasn’t sufficient for L4 load balancers,” he explains. “L4 load balancers process packets at an extremely fast rate, and I wanted to create a tool specifically optimized for this purpose. It had to be simple, efficient, and high-performing.”
The turning point came when Jianzhang participated in a hackathon at Baidu in 2021. “The hackathon provided the perfect opportunity to develop the first version of DPERF,” he shares. “Although I didn’t win, the experience gave me the passion and motivation to continue refining the tool.” Despite the initial lack of recognition, his colleagues and teammates appreciated the significance of his work. “They knew it was a great project, even if others didn’t realize it at the time,” Jianzhang reflects.
“The hackathon provided the perfect opportunity to develop the first version of DPERF,” he shares. “Although I didn’t win, the experience gave me the passion and motivation to continue refining the tool.”
Fueled by his hackathon experience, Jianzhang dedicated himself to creating a lightweight, high-performance tester tailored to L4 load balancers. This marked the beginning of DPERF, a tool that would soon make an impact in the DPDK community.
From Concept to Version One
The first version of DPERF was completed in just two weeks. Jianzhang describes this period as “crazy,” working tirelessly from early morning until midnight every day. “The initial codebase was less than 5,000 lines,” he shares. “I wrote it all myself, focusing on simplicity and performance.”
At the outset, Jianzhang envisioned importing the TCP stack from FreeBSD but quickly realized that the task was too large to complete within the hackathon’s timeframe. “Then, an idea struck me—to simplify the TCP stack,” he recalls. “I focused on identifying which parts could be streamlined while still maintaining the essential functionality.”
Then, an idea struck me—to simplify the TCP stack,” he recalls. “I focused on identifying which parts could be streamlined while still maintaining the essential functionality.”
Jianzhang credits this breakthrough to inspiration and his deep experience with L4 load balancing. “I designed the most important components of the architecture in just a few minutes,” he says. “From there, I refined and simplified every part of the TCP stack to meet the performance goals.”
The intensity of this period took a physical toll, as Jianzhang recalls experiencing repetitive strain injuries from non-stop coding. Despite this, he describes the process as exhilarating. “I was so passionate about the project that I enjoyed every moment of it,” he says. “It was incredible to see the tool take shape so quickly.”
Jianzhang’s approach was unique in that he didn’t follow a conventional development workflow. Instead of iterating through a structured design-test-refine process, he coded the entire tool in one go. “I just started and worked all the way through to the end,” he explains. “It was all about maintaining focus and momentum.”
“I just started and worked all the way through to the end,” he explains. “It was all about maintaining focus and momentum.”
Optimizing and Refining DPERF
Following the initial release, Jianzhang continued to optimize DPERF. With over a decade of experience working with user-space TCP stacks, he applied his deep knowledge of L4 and L7 load balancers to improve performance further. “I knew how to integrate L2, L3, L4, and L7 into a simplified stack,” he explains. “This allowed me to create a highly efficient and scalable solution.”
The architecture of DPERF consists of a client-server model where each CPU independently handles packet transmission and reception. This design ensures that CPUs do not need to share state, significantly improving performance. “Each CPU sends and receives its own packets,” Jianzhang details. “This way, we eliminate unnecessary inter-CPU communication and maximize efficiency.”
A key innovation in DPERF is the caching mechanism for packet headers. “Instead of regenerating the entire packet for each test, we cache the payload and only modify the necessary header fields,” Jianzhang explains. “This drastically reduces processing overhead and enhances performance.”
“Instead of regenerating the entire packet for each test, we cache the payload and only modify the necessary header fields,”
Another critical optimization is the use of a pre-allocated socket table. “All sockets are created at the beginning,” he says. “This allows us to instantly locate sockets based on IP addresses and ports, ensuring rapid packet processing.”
Through continuous refinement and feedback from users, DPERF evolved into a highly reliable and high-performance tool, widely adopted in production environments.
Reflections on the DPDK Community and Open Source
While deeply involved in DPERF, Jianzhang’s contributions to the broader DPDK project have been limited due to his current role in a crypto trading company. “If I worked at a networking-focused company, I might engage more directly with the DPDK community,” he reflects. “But I still appreciate the support from my company, which allows me to continue maintaining DPERF as an open source project.”
When asked about the growth of DPDK adoption in Asia, Jianzhang acknowledges its increasing use, particularly among network device manufacturers and cloud service providers. “A lot of companies are using DPDK for firewalls, security applications, and cloud networking,” he says.
“A lot of companies are using DPDK for firewalls, security applications, and cloud networking,”
He also notes that some major technology firms—including TikTok (ByteDance), Baidu Cloud, and Alibaba Cloud—use DPERF internally, though these details are not publicly shared. “Many companies rely on open source software without publicly acknowledging it,” he says. “But knowing that DPERF is helping real-world deployments is what matters most to me.”
“But knowing that DPERF is helping real-world deployments is what matters most to me.”
Advice for Aspiring Open Source Developers
As a respected developer in the DPDK ecosystem, Jianzhang offers advice for those looking to follow in his footsteps. “Develop something truly useful,” he says. “If it helps you and others solve real-world problems, it has value.”
“Develop something truly useful,” he says. “If it helps you and others solve real-world problems, it has value.”
He also emphasizes the importance of persistence and passion. “Building an open source project isn’t easy,” he says. “But if you believe in what you’re creating, keep refining it, keep listening to feedback, and keep pushing forward.”
“Building an open source project isn’t easy,” he says. “But if you believe in what you’re creating, keep refining it, keep listening to feedback, and keep pushing forward.”
Jianzhang’s journey—from solving a personal technical challenge to developing a widely used open source tool—highlights the impact of individual contributions in the DPDK community. His work on DPERF has not only improved network performance testing but also demonstrated the power of innovation and collaboration.

Introduction:
Grout is an emerging open source project hosted under the DPDK community that aims to simplify high-performance networking and provide a reference application for building applications using DPDK. Spearheaded by Robin Jarry from Red Hat, the project was born out of the need for a vendor-neutral, practical tool to validate server setups optimized for DPDK performance.
This user story dives into the origins, challenges, and aspirations of the Grout project.
Building Grout to Simplify High-Performance Networking
Robin Jarry, a software engineer at Red Hat and member of the OpenStack NFV Integration team, has been at the forefront of tackling the intricate challenges of deploying high-performance networking solutions. Based in France, Robin works primarily with telco customers, focusing on tasks like power tuning, CPU isolation, and configuring servers to maximize the performance of DPDK.
While these optimizations are critical for achieving the desired results, validating the setups proved to be a recurring issue in his work. The tools available, such as testpmd, were limited in scope. Although testpmd is a valuable application for testing DPDK drivers, it lacks networking functionality and cannot fully verify the correctness of server configurations.
Recognizing this gap, Robin and his colleagues decided to create a solution that could act as a vendor-neutral application for validating DPDK-based server setups. This effort gave rise to Grout, a project designed to simplify and standardize the use of DPDK in high-performance environments.
Like any new project, the early stages of Grout were challenging, with foundational work requiring significant effort. However, once the initial framework was laid out, the team found it increasingly easy to add new features and protocols. Their hard work culminated in a presentation Grout # a Graph Router Based on DPDK at the DPDK Summit North America 2024 event, where Robin and key contributor David Marchand received overwhelmingly positive feedback.
“I was thrilled by how well Grout was received, the feedback during and after the talk confirmed that we’re solving a real problem, and it’s exciting to see the community’s enthusiasm for this project.”
Robin credits the project’s success not only to his efforts but also to the collaboration with key contributors, including David Marchand, a long-time DPDK maintainer, and Christophe Fontaine, a colleague at Red Hat.
Christophe focuses on OpenStack engineering for Telco use cases, leading the design of Network Functions Virtualization (NFV) within the OpenStack team to optimize high-performance connectivity for Virtual Network Functions (VNFs) and Cloud-Native Functions (CNFs). Before joining Red Hat, he worked at Qosmos (ENEA), where he contributed to FD.io and OpenDaylight, enhancing dynamic service function chaining for OpenStack on x86 and ARM servers.
Additionally, Christophe has provided detailed documentation, engaged with the community, and shared insights on performance tuning and Grout integration at DPDK summits, making advanced features more accessible to both new and experienced users.
Together, they are pushing Grout forward as a reference application for DPDK, designed to simplify its adoption and showcase best practices for achieving high performance in networking workloads.
Robin’s path to becoming a key contributor in the DPDK community is anything but conventional. Before writing code and configuring high-performance servers, Robin was immersed in a completely different world: the music industry. Working as a sound engineer in Brussels, Robin honed his technical skills in an environment that demanded precision and creativity. However, financial challenges forced him to make a career change—a decision that ultimately led him to software engineering and the open source world.
“I had to start from scratch,” Robin shared. “I went to night school, earned my engineering degree, and began exploring what I could do in the world of technology.”
The Connection Between Music and Code
Interestingly, Robin sees parallels between his past career as a sound engineer and his work as a software engineer. Both disciplines require problem-solving, creativity, and a focus on building something that works seamlessly. “There’s a certain creative energy in both fields. Coding feels like crafting something, almost like creating music, where every piece fits together to form a complete whole.”
“There’s a certain creative energy in both fields. Coding feels like crafting something, almost like creating music, where every piece fits together to form a complete whole.”
Robin’s unique perspective isn’t uncommon in the tech world. A recent poll by another Linux Foundation project revealed that nearly 38% of developers are also musicians—a convergence that highlights the shared skills of discipline, creativity, and focus. For Robin, this duality reinforces the idea that diverse backgrounds can bring fresh perspectives to technical challenges.
A recent poll by another Linux Foundation project revealed that nearly 38% of developers are also musicians—a convergence that highlights the shared skills of discipline, creativity, and focus.
Robin’s first exposure to open source came from an unexpected place: side projects in video game development. While exploring these projects, he became captivated by the ethos of open source. “What struck me was how these developers were building software for free, just to help others and share knowledge. I wanted to understand their mindset, and it resonated deeply with me,” Robin explained.
“What struck me was how these developers were building software for free, just to help others and share knowledge. I wanted to understand their mindset, and it resonated deeply with me,”
This philosophy of collaboration and giving back to the community would become a cornerstone of Robin’s career. His professional journey into open source began in earnest when he joined 6WIND, the company responsible for establishing the open source DPDK community in 2013. Here, he worked on projects that blended his growing technical expertise with his newfound passion for open source development.
Over the years, Robin’s involvement with DPDK became both a professional responsibility and a personal conviction.
“I don’t just do open source work because it’s part of my job—I genuinely believe in the values of open source, it fits with my character. I enjoy the process of contributing, maintaining projects, and seeing the positive impact on the community.”
Giving Back to the Open Source Community
Robin’s commitment to open source extends beyond DPDK. In his spare time, he maintains personal projects and contributes to other open-source initiatives. He describes this as a “virtuous cycle” of giving and receiving energy: “People are often grateful when you contribute something useful, and that gratitude motivates you to keep going. It’s a positive feedback loop.”
This passion for open source is also evident in Grout, where Robin and his team have made contributions not just to their own project, but back to the DPDK ecosystem. By identifying and fixing issues within DPDK’s core libraries, they’re embodying the principles of open source collaboration.
Reflecting on his experience with DPDK, Robin praised the community’s inclusiveness and support for newcomers. “When I started contributing to DPDK about 10 years ago, I found it much more welcoming compared to other projects, which have a steeper entry barrier,” he said. “The DPDK community is patient, helpful, and understanding—even with people who are just getting started.”
“The DPDK community is patient, helpful, and understanding—even with people who are just getting started.”
This collaborative spirit has been a key factor in Robin’s long-term involvement with DPDK, as well as his enthusiasm for helping others onboard into the ecosystem.
As the DPDK project evolves, it finds itself in a transitional phase—moving from years of foundational development into a focus on real-world applications and use cases. Grout, a new addition to the DPDK ecosystem, is emerging as a key project in this transformation.
The origins of Grout lie in the complexity of getting started with DPDK. While DPDK has been a pioneering project for high-performance networking, its setup process can be daunting. “You have too many things to configure,” Robin explained, “from enabling VFIO and allocating huge pages to binding devices to the right drivers. It’s complex, and people have told us that this is one of the biggest hurdles.”
“You have too many things to configure, from enabling VFIO and allocating huge pages to binding devices to the right drivers. It’s complex, and people have told us that this is one of the biggest hurdles.”
Grout is designed to simplify this experience. It aims to serve as a reference example—a guide to using DPDK libraries in a clean, best-practice-driven way. This includes demonstrating how to configure networking for high performance or even integrate AI applications using DPDK.
Robin highlighted that the DPDK community is keenly aware of this need. “We’ve received a lot of feedback asking for either best practices or an example of how things are intended to be used. Grout could become that example—a model of how DPDK can be leveraged effectively and efficiently.”
Grout isn’t starting from scratch. One of its core building blocks is the DPDK Graph Library, which provides a structured approach for building applications. According to Robin, the Graph Library already delivers roughly “a third of the structure needed to build a DPDK application.”
This modularity makes Grout not only a great starting point but also a potential framework for future DPDK projects. By leveraging existing tools and adding layers of usability, Grout is poised to streamline development for other contributors and users.
“Part of this foundation is already in DPDK itself,” Robin said, emphasizing that Grout’s architecture is tightly integrated with existing libraries, making it an ideal reference point for those entering the ecosystem.”
The feedback from the DPDK community underscores the importance of Grout’s focus on usability and practical application. As DPDK transitions from being a toolkit to supporting more application-level use cases, projects like Grout play an essential role in bridging the gap.
This shift is especially relevant as the networking world increasingly embraces cloud-native technologies. Grout’s primary use case targets container-native and cloud-native network functions (CNFs), making it a valuable asset for telcos and enterprises deploying high-performance networking in OpenStack, Kubernetes, and OpenShift environments.
“Grout isn’t a replacement for other tools like OVS, but it’s designed to run in VMs or containers, rather than on a host server. Its focus is entirely different—Grout is a router, not a virtual switch.”
Grout is still in its early stages, but its potential is already clear. By addressing pain points in the DPDK ecosystem and providing a practical, scalable reference architecture, it paves the way for easier adoption and innovation. Whether it’s serving as a blueprint for building high-performance CNFs or simplifying the onboarding process for new contributors, Grout is an important part of the next chapter of DPDK.
With its foundations rooted in the community and a focus on usability and real-world applications, Grout exemplifies the values of open source development. As Robin aptly put it,
“Grout is here to simplify, to guide, and to inspire what’s possible with DPDK.”
Grout’s target use case is clear: cloud-native network functions (CNFs) and container-native network functions. These applications are vital for telcos and high-performance networking environments but represent a niche within the broader world of cloud computing.
Robin contrasted this with the dominant web application model in the cloud. “A web service won’t really be affected by Grout,” he noted. “But for telco applications or high-performance networking, where the requirements are far more specialized, Grout provides the extra care needed.”
While this niche focus may seem limiting at first glance, it’s precisely this specialization that makes Grout so valuable. By addressing the unique challenges of high-performance networking, Grout fills a critical gap in the DPDK ecosystem.
“A web service won’t really be affected by Grout,” he noted. “But for telco applications or high-performance networking, where the requirements are far more specialized, Grout provides the extra care needed.”
As Grout evolves, its focus remains on bridging gaps in the DPDK ecosystem and addressing specific use cases that demand high-performance networking. While not directly tied to AI or machine learning, Grout contributes to the infrastructure that supports automation and efficiency, helping simplify workflows and creating a foundation for innovation.
For instance, Grout could play a role in automating aspects of testing or continuous integration (CI) processes in environments requiring high-performance networking. By providing a standardized reference for DPDK applications, it could ensure seamless interactions between hardware and software, laying the groundwork for advanced automation tasks.
In the short term, Grout’s primary contribution is its role as a reference for building containerized, high-performance network functions. Long-term, its automation and usability features could influence broader workflows, including testing, CI pipelines, and operational efficiency in telco and enterprise environments.
By simplifying the complexities of DPDK setups and offering clear examples of best practices, Grout is poised to make high-performance networking more accessible—not just for seasoned developers, but for newcomers to the ecosystem as well.
Having reached its minimum viable product (MVP) stage, Grout’s next steps focus on usability. Robin outlined several key areas for improvement, emphasizing the need to simplify tasks that currently require manual intervention.
One prominent feature on the roadmap is the automatic assignment of port RX queues to CPUs. “Right now, this is something you need to configure manually, but automating this will make the setup process much easier,” Robin said. This improvement would make Grout more accessible to users deploying DPDK applications in cloud environments, whether in OpenStack, OpenShift, or Kubernetes.
Another goal is to refine Grout’s role as a reference application—a good example of how DPDK libraries and tools should be used. By demonstrating best practices, Grout aims to set a standard for developers, helping them build applications without grappling with unnecessary complexity.
As for the future, Robin believes that Grout will evolve based on community needs and feedback. “Maybe it will serve as an example, as a reference architecture,” he said. “I don’t want to overstate its impact—it’s going to evolve organically based on how the community uses it.”
“Maybe it will serve as an example, as a reference architecture,” he said. “I don’t want to overstate its impact—it’s going to evolve organically based on how the community uses it.”
This flexible approach reflects the open source mindset at the heart of Grout’s development. Rather than dictating its direction, Robin and his team are focused on providing a solid foundation and letting the project grow in response to real-world use cases.
As Grout continues to evolve, it stands as a testament to the power of open source collaboration. Whether serving as a blueprint for DPDK applications, simplifying cloud-native networking setups, or enabling automation in niche use cases, Grout demonstrates how focused, community-driven efforts can lead to impactful tools that solve real problems.
In Robin’s words, “Grout isn’t trying to be everything, but by focusing on what it does best—providing clarity and structure—it has the potential to make a lasting difference in the DPDK ecosystem.”
“Grout isn’t trying to be everything, but by focusing on what it does best—providing clarity and structure—it has the potential to make a lasting difference in the DPDK ecosystem.”
At Red Hat, DPDK plays a critical role, particularly in conjunction with Open vSwitch (OVS). However, Grout occupies a distinct niche in this ecosystem. “OVS runs on the host, while Grout is designed to run in VMs or containers, It’s not meant to replace OVS; it’s a router, not a virtual switch. The scopes are entirely different.”
Grout aligns with Red Hat’s strategy to develop examples of virtual network functions (VNFs) and cloud-native network functions (CNFs) that demonstrate DPDK’s capabilities. While Grout is still in its early stages, its development reflects an experimental approach: build something, see if it gains traction, and adapt based on feedback.
This iterative mindset mirrors the ethos of open source—collaborate, experiment, and refine based on community needs.
The DPDK community has long emphasized the importance of integrating its technology with other open-source projects, and Grout exemplifies this philosophy.
Robin highlighted Kubernetes as a natural integration point for DPDK, given the growing adoption of containerized environments in networking. “Kubernetes is an obvious pathway for collaboration, especially for projects like Grout that target container-native applications,” he noted.
“Kubernetes is an obvious pathway for collaboration, especially for projects like Grout that target container-native applications”.
Additionally, Grout has facilitated a reverse flow of contributions—where challenges encountered during Grout’s development led to improvements in the DPDK core itself. This reciprocal relationship underscores the project’s commitment to the principles of open source: contribute back to what you use.
“Instead of just consuming DPDK, we’ve raised issues, fixed them, and sent patches back to the community,” Robin said. “This approach isn’t just rewarding; it’s essential for maintaining the ecosystem’s vitality.”
Raising Awareness and Building Momentum
Looking ahead, Robin sees opportunities to raise awareness about Grout and its role in the DPDK ecosystem. Collaborating with organizations like the Linux Foundation and participating in events can help showcase the project’s potential. As Robin summed it up, “Grout is as much about helping others as it is about building something new. It’s a shared effort, and that’s what makes it special.”
“Grout is as much about helping others as it is about building something new. It’s a shared effort, and that’s what makes it special.”
To get involved, join the mailing list at grout@dpdk.org, explore the project on GitHub at https://github.com/DPDK/grout, and share your ideas for how you’d like to use Grout!
Don’t forget to catch the Grout presentation at FOSDEM 2025 on February 2.

The demand for high-performance network security solutions is at an all-time high, as organizations constantly seek faster and more efficient ways to handle traffic, detect threats, and ensure real-time response capabilities.
Suricata as an open-source high-performance network security engine has long been at the forefront of these efforts. Network security professionals appreciate Suricata for its capabilities to act as an IDS (Intrusion Detection System), IPS (Intrusion Prevention System), and as an NSM (Network Security Monitoring) system.
But it’s the integration of the Data Plane Development Kit (DPDK) into Suricata that has allowed it to reach unprecedented performance levels, providing a vital boost for packet processing at high speeds.
This story explores the journey of Suricata’s DPDK integration, the technical challenges and solutions, and the ongoing impact on Suricata’s functionality and performance.
In 2008, a group of security-focused professionals came together with a vision to improve open-source network security.
Victor Julien, who was working as a contractor in the network security field, joined forces with Matt Jonkman, who led an early threat intelligence project (known as Emerging Threats), and Will Metcalf, who was involved in developing an inline version of Snort—a popular intrusion detection and prevention system (IDS/IPS).
Their collaborative work in network security sparked the idea to create something new that would address gaps in existing solutions.
The journey truly began when Victor experimented with code on his own in 2007, without expecting much traction. However, after meeting Matt and Will at a conference in the U.S. and sharing his prototype with them, the project gained momentum.
By 2008, they secured initial seed funding from the Department of Homeland Security (DHS), allowing them to pursue their vision formally. This funding was instrumental in establishing the Open Information Security Foundation (OISF), a nonprofit entity designed to ensure that the project would remain community-oriented and free from corporate control.
From the start, they were committed to making Suricata an open-source, community-driven project. With the OSF foundation’s setup, they chose the GPLv2 license, reflecting their belief in open collaboration and safeguarding the project from being absorbed by larger corporations. DHS funding, while crucial, was temporary, so they developed a sustainable model that allowed vendors to join OSF as members, offering a more flexible licensing option.
This foundational approach set the stage for what has now been a 15-year journey of innovation and collaboration in the network security field.
“We wanted to establish an organization that would make Suricata safe from acquisition, which we’d seen happen to other open-source projects at the time.”
– Victor Julien – Suricata IDS/IPS Lead Developer
Since then, Suricata has gained adoption from large enterprises, including AWS, which integrates Suricata in its network firewall services.
With increasing demand for high-performance network security tools, Suricata’s team saw an opportunity to leverage DPDK. DPDK provides a set of libraries and drivers for fast packet processing, bypassing traditional kernel limitations.
This high-performance potential caught the attention of users and developers alike, many of whom were eager to see DPDK integration in Suricata. Lukas Sismis, a contributor who led Suricata’s DPDK integration, explained that several teams had previously worked on integrating DPDK with Suricata.
However, most of these efforts were specific to unique use cases and lacked general applicability, which is why they hadn’t been contributed back to the Suricata codebase.
Lukas initially engaged with Suricata’s architecture through a master’s thesis, where his primary goal was to expand Suricata’s packet capture capabilities using DPDK. He explains, “Suricata’s architecture, with its separate capture logic, made it easy to add a new capture method.”
His work, later incorporated into Suricata’s main codebase, helped create a general-purpose DPDK integration, ensuring Suricata’s compatibility with multiple DPDK-supported network interface cards (NICs) and enabling seamless configuration.
“Suricata’s architecture, with its separate capture logic, made it easy to add a new capture method.”
– Lukas Sismis, Software Engineer at Suricata & Cesnet
Suricata’s multi-threaded, modular design made it an ideal candidate for integration with DPDK. Suricata supports packet-capturing methods through its modular “capture interface,” which allows users to swap out packet capture techniques.
DPDK, as an input method, fits naturally within this design and supports Suricata’s scalability goal: Suricata aims to run effectively across small, low-power deployments to high-speed data centers.
Lukas’ integration efforts involved setting up DPDK within Suricata as an alternative capture method, making it possible to directly interface with high-speed NICs while bypassing kernel overhead. Some of the major steps in this integration included:
While most initial optimizations focused on enabling basic packet capture, this work laid the foundation for further enhancements. Testing showed a notable 10-15% performance gain, an exciting outcome that validated the decision to integrate DPDK as a core feature of Suricata’s capture options.
Beyond standard packet capture, the Suricata team recognized a significant opportunity in DPDK’s hardware offloading capabilities. Suricata’s high-speed packet processing can greatly benefit from the offloading of repetitive tasks to hardware, potentially bypassing certain types of network traffic.
Lukas and his team began exploring offload capabilities that would allow Suricata to selectively filter traffic in hardware.
The primary focus of Suricata’s hardware offloading research has been on:
Although full offload implementation is still underway, initial testing shows promising potential. DPDK’s RegEx accelerator API, supported by NVIDIA BlueField and Marvell NICs, is an example of hardware that could handle pattern-matching offloads. This ongoing work has been presented at Suricon 2024.
Since Suricata’s detection engine performs extensive pattern matching, a hardware-based solution could significantly reduce CPU load.
Lukas encountered several challenges while working with DPDK, primarily related to hardware compatibility and traffic distribution. While DPDK offers a standardized API, not all NICs perform identically, which led to variations in performance during testing.
One challenge was to cover and unify the different configurations of the load balancing hash function (RSS) in the NICs. This required NIC-specific experimentation and testing with different configuration mechanisms.
Lukas also had to modify Suricata’s configuration parsing to map settings to DPDK-compatible options, ensuring a more user-friendly experience.
This testing phase highlighted the need for adaptable configurations to support a wide range of DPDK-enabled hardware.
Despite these challenges, Lukas’ integration work has laid a strong foundation for Suricata’s use of DPDK, making Suricata more adaptable to high-performance environments.
Suricata’s community engagement plays a vital role in its development. Lukas worked closely with the CESNET team, a network research institution with deep experience in DPDK.
This collaboration allowed him to troubleshoot issues in real time without relying solely on online forums. In addition, Victor and Lukas sought feedback from DPDK maintainers like Thomas Monjalon and David Marchand, whose insights were invaluable in refining Suricata’s integration.
Suricata’s developers also participate in community channels, including a Discourse forum, Redmine, and a Discord server. While direct communication with the DPDK team has been limited, Suricata’s community-driven model allows users to share feedback directly with developers, accelerating improvements and ensuring the tool meets evolving needs.
DPDK’s integration has brought measurable performance gains to Suricata, providing faster packet processing for users. Major security vendors are already leveraging Suricata with the DPDK integration in their products, attesting to its reliability and scalability.
DPDK’s impact is particularly evident in high-speed environments where packet capture bottlenecks could otherwise lead to packet drops or latency. The integration allows Suricata to handle higher packet rates efficiently, extending its utility in demanding, real-time network security use cases.
As artificial intelligence and machine learning applications expand across technology sectors, Suricata’s team remains open to exploring AI-driven enhancements.
Victor explained that AI’s most promising role would likely be in post-processing. Suricata currently exports JSON-formatted data, which can be fed into AI models for insights beyond immediate packet inspection.
Many current machine learning models operate at a macro level, analyzing data patterns over time rather than in real time, which aligns well with Suricata’s current functionality as a data generator for other analytics tools.
Real-time AI inference for packet processing, however, remains a challenge. Victor elaborated, “Most AI models require milliseconds for inference, which is too slow for packet-level detection in real-time.” Still, the team is ready to adopt AI models once hardware advances make real-time AI feasible.
“Most AI models require milliseconds for inference, which is too slow for packet-level detection in real-time.”
–– Victor Julien – Suricata IDS/IPS Lead Developer
A major long-term goal for Suricata is to establish a core API, effectively transforming Suricata’s detection engine into a library that other tools can leverage.
This approach could enable seamless integration of Suricata’s capabilities with other applications, such as proxy servers, endpoint security products, and cloud-based services.
While the foundational work for this API exists, achieving a fully developed API will take time. Victor noted that this goal, motivated by growing encryption in network traffic, could broaden Suricata’s utility in increasingly secure environments.
This library initiative would allow third-party developers to incorporate Suricata’s detection features in novel ways, creating a flexible, modular ecosystem where Suricata is part of larger, more complex security infrastructures.
Suricata’s annual conference, Suricon, exemplifies the project’s community-centric approach. Suricon gathers developers, users, and industry professionals to share insights, discuss roadmap goals, and showcase new features.
With a mix of training sessions and talks, Suricon provides a valuable opportunity for knowledge exchange and collaboration. DPDK community members have shown interest in attending future events, strengthening cross-community relationships, and fostering a shared development approach.
Suricata’s collaboration model has proven instrumental in its growth. This strong community foundation ensures that Suricata can keep pace with rapidly changing security demands.
Suricata’s integration with DPDK marks a significant milestone in its evolution, empowering it to achieve higher performance, greater adaptability, and better hardware compatibility.
From initial testing to real-world deployments, DPDK’s impact has been transformative, enabling Suricata to meet the demands of today’s high-speed, security-focused networks.
Through community feedback, industry collaboration, and a forward-looking approach to hardware offloading and AI, Suricata continues to redefine what’s possible in open-source network security.
As Suricata looks ahead, its development team remains committed to innovation and community-driven progress. With a roadmap that includes expanded hardware offloading, AI-driven enhancements, and new API integrations, Suricata is well-positioned to lead the next generation of network security solutions.
This DPDK integration story exemplifies how open-source collaboration can drive meaningful advancements, pushing technology forward in response to real-world needs.
Learn more about contributing to DPDK here

Introduction
In the modern cloud computing era, network performance and efficiency are paramount. Microsoft Azure has been at the forefront of this revolution, introducing innovative solutions like the Microsoft Azure Network Adapter (MANA) and integrating the Data Plane Development Kit (DPDK) to enhance the network capabilities of Azure virtual machines.
In this user story we interview Brian Denton, and Matt Reat, Senior Program Managers for Azure Core. Brian’s role has been pivotal, focusing on engaging with all network virtual appliance partners to ensure they are prepared and supported for the introduction of a new Network Interface Card (NIC) into Azure.
Matt’s journey at Microsoft began primarily within the networking domain. His career commenced with network monitoring before transitioning, about four years ago, into what is referred to as the host networking space. This area encompasses the SDN software stack and hardware acceleration efforts aimed at enhancing customers’ ability to utilize an open virtual network (OVN) and improve their overall experience on Azure.
A natural progression of his work has involved spearheading innovations in software and the development of hardware, which have recently been introduced to the public as Azure Boost. Additionally, his contributions include the development of the MANA NIC, a product developed in-house at Microsoft.
The Genesis of Azure MANA
Azure MANA represents a leap in network interface technology, designed to provide higher throughput and reliability for Azure virtual machines. As the demand for faster and more reliable cloud services grows, Azure’s response with MANA smartNICs marks a significant milestone, aiming to match and surpass AWS Nitro-like functions in network and storage speed acceleration.
Microsoft’s strategy encompasses a comprehensive approach, with a primary focus on hardware acceleration from top to bottom. This effort involves current work being conducted on the host and in the hypervisor (Hyper-V), aiming to advance hardware capabilities. Such initiatives are also being pursued by competitors, including AWS with its Nitro system and Google with a similar project, marking Microsoft’s contribution to this competitive field.
Behind the scenes, the team implemented several enhancements that remained undisclosed until the announcement of Azure Boost last July. This development compelled them to reveal their progress, especially with the introduction of the MANA NIC, which had been concealed from customer view until then.
The introduction of the new MANA NIC, boasting ratings of up to 200 Gbps in networking throughput, represents a significant enhancement of the current Azure offerings, in-line with Microsoft’s competition. The reliance on off-the-shelf solutions proved to be cost-prohibitive, prompting a shift to a fully proprietary, in-house solution integrated with their Field-Programmable Gate Array (FPGA).
DPDK’s Role in Azure’s Network Evolution
DPDK offers a set of libraries and drivers that accelerate packet processing on a wide array of CPU architectures. Microsoft Azure’s integration of DPDK into its Linux Virtual Machines (VMs) is specifically designed to address the needs of applications that demand high throughput and low latency, making Azure a compelling choice for deploying network functions virtualization (NFV), real-time analytics, and other network-intensive workloads.
The technical essence of DPDK’s acceleration capabilities lies in its bypass of the traditional Linux kernel network stack. By operating in user space, DPDK enables direct access to network interface cards (NICs), allowing for faster data plane operations. This is achieved through techniques such as polling for packets instead of relying on interrupts, batch processing of packets, and extensive use of CPU cache to avoid unnecessary memory access. Additionally, DPDK supports a wide range of cryptographic algorithms and protocols for secure data processing, further enhancing its utility in cloud environments.
Azure enhances DPDK’s capabilities by offering support for a variety of NICs optimized for use within Azure’s infrastructure, including those that support SR-IOV (Single Root I/O Virtualization), providing direct VM access to physical NICs for even lower latency and higher throughput. Azure’s implementation also includes provisions for dynamically managing resources such as CPU cores and memory, ensuring optimal performance based on workload demands.
Microsoft’s commitment to DPDK within Azure Linux VMs underscores a broader strategy to empower developers and organizations with the tools and platforms necessary to build and deploy high-performance applications at scale. By leveraging DPDK’s packet processing acceleration in conjunction with Azure’s global infrastructure and services, users can achieve the highest possible performance on Azure.
Enhancing Cloud Networking with Azure MANA and DPDK
Azure MANA and DPDK work in tandem to push the boundaries of cloud networking. MANA’s introduction into Azure’s ecosystem not only enhances VM throughput but also supports DPDK, enabling network-focused Azure partners and customers to access hardware-level functionalities. When introducing a new Network Interface Card (NIC), it is essential to have support for the Data Plane Development Kit (DPDK). The primary concern is that Azure customers will begin to encounter Mana NICs across various Virtual Machine (VM) sizes, necessitating support for these devices. This situation highlights a notable challenge.
The scenario involves three NICs and two Mellanox drivers requiring support, indicating a significant transition. The introduction of this new NIC and its drivers is intended for long-term use. The goal is for the MANA driver to be forward-compatible, ensuring that the same driver remains functional many yearsfrom now, without the need to introduce new drivers for new NICs with future revisions, as previously experienced with ConnectX and Mellanox.
The objective is a long-term support driver that abstracts hardware changes in Azure and the cloud affecting guest VMs, offering a steadfast solution for network I/O. Although the future specifics remain somewhat to be determined, the overarching aim is to support the features available on Azure, focusing on those needs rather than the broader spectrum of Mellanox’s customer requirements. Some features necessary for Azure may not be provided by Mellanox, and vice versa. Thus, the ultimate goal is to support Azure customers with tailored features, ensuring compatibility and functionality for the long term.
Microsoft offers a wide array of networking appliances that are essential to their customers’ architectures in Azure. Therefore, part of their effort and emphasis on supporting DPDK is to ensure our customers receive the support they need to operate their tools effectively and achieve optimal performance.
Supporting DPDK is essential to accommodate those toolsets. Indeed, maximizing the use of our hardware is also crucial. This is an important point because there’s potential for greater adoption of DPDK.
Matt Reat, Senior Program Manager at Microsoft
Typically, Microsoft’s users, mainly those utilizing network virtual appliances, leverage DPDK, and they are observing increased adoption not only among Microsoft’s Virtual Academy’s but also among customers who express intentions to use DPDK. It’s not limited to virtual appliance products alone. They also have large customers with significant performance requirements who seek to maximize their Azure performance. To achieve this, leveraging DPDK is absolutely essential.
The Technicals of MANA and DPDK
The MANA poll mode driver library (librte_net_mana) is a critical component in enabling high-performance network operations within Microsoft Azure environments. It provides specialized support for the Azure Network Adapter Virtual Function (VF) in a Single Root I/O Virtualization (SR-IOV) context. This integration facilitates direct and efficient access to network hardware, bypassing the traditional networking stack of the host operating system to minimize latency and maximize throughput.
By leveraging the DPDK (Data Plane Development Kit) framework, the MANA poll mode driver enhances packet processing capabilities, allowing applications to process network packets more efficiently. This efficiency is paramount in environments where high data rates and low latency are crucial, such as in cloud computing, high-performance computing, and real-time data processing applications.
The inclusion of SR-IOV support means that virtual functions of the Azure Network Adapter can be directly assigned to virtual machines or containers. This direct assignment provides each VM or container with its dedicated portion of the network adapter’s resources, ensuring isolated, near-native performance. It allows for scalable deployment of network-intensive applications without the overhead typically associated with virtualized networking.
Overall, the technical sophistication of the MANA poll mode driver library underscores Microsoft Azure’s commitment to providing advanced networking features that cater to the demanding requirements of modern applications. Through this library, Azure ensures that its cloud infrastructure can support a wide range of use cases, from web services to complex distributed systems, by optimizing network performance and resource utilization.
“The MANA poll mode driver library, coupled with DPDK’s efficient packet processing, allows us to optimize network traffic at a level we couldn’t before. It’s about enabling our customers to achieve more with their Azure-based applications.”
Matt Reat, Senior Program Manager at Microsoft
The setup procedure for MANA DPDK outlined in Microsoft’s documentation provides a practical foundation for these advancements, ensuring that users can leverage these enhancements with confidence. Furthermore, the support for Microsoft Azure Network Adapter VF in an SR-IOV context, as implemented in the MANA poll mode driver library, is a testament to the technical prowess underlying this integration.
Performance Evaluation and Use Cases
Evaluating the performance impact of MANA and DPDK on Linux VMs highlights significant improvements in networking performance. Azure’s documentation provides insights into setting up DPDK for Linux VMs, emphasizing the practical benefits and scenarios where the combination of MANA and DPDK can dramatically improve application responsiveness and data throughput.
Microsoft effectively utilizes the Data Plane Development Kit (DPDK) on the host side to optimize network performance across its Azure services. This approach not only supports customer applications by enhancing the speed and efficiency of data processing on virtual machines but also strengthens Microsoft’s own infrastructure.
By leveraging DPDK, Azure can handle higher data loads more effectively, which is crucial for performance-intensive applications. For a deeper understanding of how DPDK facilitates these improvements in cloud computing, view the latest webinar, “Hyperscaling in the Cloud,” which discusses the scale and scope of DPDK’s impact on Azure’s network architecture.
“We’re aiming to push the boundaries of network performance within Azure, leveraging MANA alongside DPDK to achieve unprecedented throughput and reliability for our virtual machines.”
Brian Denton, Senior Program Manager, Microsoft Azure Core
Significant emphasis is placed on the first 200 gig NIC, highlighting a substantial focus on achieving high throughput. Additionally, the necessity to support a high packet rate stands as a corollary to this objective. To comprehend and benchmark their throughput across various packet sizes, extensive work is undertaken. DPDK serves as the primary method for testing their hardware in this regard.
Microsoft’s engineering counterparts focus on the overall testing methodology for developing a DPDK driver set, as well as testing the hardware itself and the VM performance on that hardware. This includes client-side involvement in testing. Currently, only Linux is officially supported for DPDK, although there have been attempts to use Windows and FreeBSD. Various host configurations also play a crucial role in qualifying their hardware.
Future Directions and Community Engagement
As Azure continues to evolve, the collaboration between Microsoft’s engineering teams and the open-source community remains vital. The development of MANA and its integration with DPDK reflects a broader commitment to open innovation and community-driven improvements in cloud networking.
Conclusion
As Microsoft Azure continues to evolve, the partnership between Microsoft’s engineering teams and the DPDK open-source community is poised to play a crucial role in shaping the future of cloud networking. The development of the Microsoft Azure Network Adapter (MANA) and its integration with the Data Plane Development Kit (DPDK) underscore a commitment to leveraging open innovation and fostering community-driven advancements.
The future role of Azure MANA, in conjunction with the DPDK community, is expected to focus on breaking new technical limits in cloud networking. This collaboration could lead to significant enhancements in network performance, including higher throughput, reduced latency, and greater efficiency in packet processing. By leveraging DPDK’s efficient packet processing capabilities alongside the hardware acceleration offered by MANA, Azure aims to provide an optimized networking stack that can meet the demanding requirements of modern applications and services.
Moreover, this is likely to drive the development of new features and capabilities that are specifically tailored to the needs of Azure’s diverse user base. This could include advancements in virtual network functions (VNFs), network function virtualization (NFV), and software-defined networking (SDN), which are essential components in a cloud-native networking landscape.
The open-source nature of DPDK also ensures that the broader community can contribute to and benefit from these developments, promoting a cycle of continuous improvement and innovation. This collaborative approach not only enhances the capabilities of Azure’s networking services but also contributes to the evolution of global cloud networking standards and practices.
Ultimately, the future of Microsoft Azure MANA and the DPDK open-source community is likely to be characterized by the breaking of current technical barriers, the introduction of groundbreaking networking solutions, and the establishment of Azure as a leading platform for high-performance, cloud-based networking services.
Check out the summary and additional use cases on Hyperscaling in the Cloud here.
Join the community on slack here.

In the rapidly evolving landscape of silicon and networking technologies, providing robust and standardized support for hardware has become a paramount aspect of success. Marvell, a leading provider of silicon solutions, embarked on a transformative journey to ensure seamless support for their Octeon system-on-chip (SoC) through the adoption of DPDK (Data Plane Development Kit).
This open source framework has emerged as the primary vehicle for Marvell’s silicon support, enabling the integration of sophisticated high-bandwidth accelerators with various applications. This user story dives deep into Marvell’s experiences, showcasing their transition from a chaotic ecosystem to standardized silicon support, and the significant role DPDK played in this evolution.
For this user story we interviewed Prasun Kapoor (AVP of Software Engineering), an accomplished professional with a wealth of experience in software engineering and semiconductor technologies. With a strong background in leading-edge technologies, Prasun has played a pivotal role in shaping the landscape of silicon solutions and networking technologies. As a seasoned AVP of Software Engineering at Marvell, Prasun has demonstrated exceptional leadership and expertise in driving innovation and fostering collaboration within the industry.
Chaos to Standardization: Overcoming Legacy Code Bases
When Marvell (at the time Cavium) launched its first packet acceleration and security focused multi-core SoC, there was no DPDK. Marvell implemented its own proprietary HAL library, which provided a programming interface very close to the hardware to the end users.
Many customers implemented large applications built on top of this HAL library and many times forked and customized it to suit their purposes.
However, transitioning between different silicon generations often disrupted customer applications due to minor changes in the hardware’s programming interface. This challenge was exacerbated by Cavium’s reluctance to make source code for this HAL layer available publicly or contribute it to any open-source project. This prevented Cavium from adopting DPDK from the very beginning.
The turning point for them came about in 2012-13 when they decided to create a server product. This step forced them to realize the importance of conforming to standard specifications for both hardware and software. It quickly became clear that they would not attract customers without supporting the broader software ecosystem. The previous strategy of relying solely on homegrown solutions was no longer sustainable.
Recognizing the need for a standardized library, Marvell turned to DPDK, an open and collaborative specification for networking and packet processing. By adopting DPDK at the project’s inception, Marvell aimed to provide its customers with a stable and predictable programming interface, eliminating compatibility issues when transitioning between silicon generations. The decision to align with DPDK was a fundamental shift for Marvell, enabling them to provide seamless support for their silicon.
Embracing DPDK and Collaborative Contributions
This shift to open source wasn’t merely a preference but a hard requirement, particularly in the 5G domain. Vendors in the wireless space required every piece of software provided to them to be upstreamable and upstream. This shift indicated a significant decrease in tolerance for proprietary APIs. Cavium’s first foray into open source APIs started with the Open Data Plane (ODP) project, but they adopted DPDK shortly thereafter given the much wider adoption of that framework.
While the journey to open source had its initial recalcitrance, it proved beneficial from a business perspective. Moreover, the transition to the Data Plane Development Kit (DPDK), an open-source set of libraries and drivers for fast packet processing, was monumental.
This transition saw Marvell going from a somewhat chaotic system of conflicting proprietary systems to a streamlined operation with enhanced inter-system compatibility and fluidity. The transition also had significant implications for Return on Investment
“Open-source development is not just a trend; it’s a necessary strategy for technological growth and customer satisfaction. By embracing open-source, Marvell could navigate the complexities of the tech market and build a more sustainable business model.”
Prasun Kapoor, Assistant Vice President – Software Engineering at Marvell Semiconductor
Indeed, the push towards open-source has helped Marvell build a more robust relationship with its customers. The company now engages in regular discussions with its customers, ensuring that every piece of software supplied aligns with their needs and is upstreamable. This level of transparency and collaboration has been invaluable in nurturing customer trust and fostering long-term relationships.
Marvell’s adoption of DPDK went beyond conforming to the specifications. They actively participated in the DPDK community, collaborating with other vendors to propose RFCs and extend the specifications. This approach allowed Marvell to integrate their unique accelerators and technologies into the DPDK framework, ensuring that their hardware was well-supported and widely usable. This enabled the end users to have a single application programming interface to program different class of devices such as ASIC, FPGA or SW for a given workload acceleration.
From the inception of the DPDK project, Marvell recognized the openness and receptiveness of the DPDK community to quality contributions. Initially, many of Marvell’s accelerators had no proper representation in the DPDK APIs.
As a result, Marvell worked diligently to propose RFCs and establish common API infrastructures that catered to the needs of the entire ecosystem. This collaborative effort ensured that all vendors could leverage the benefits of the standardized APIs and maximize their hardware capabilities.
Marvell’s commitment to collaborative contributions, rather than relying on proprietary APIs, helped establish a level playing field within the DPDK community. They actively extended the specifications and submitted their advancements, ensuring a robust and comprehensive framework for all users. Over the years, Marvell’s contributions have resulted in a vast array of accelerators, such as event accelerator, machine learning accelerators, cryptographic accelerators, memory pool managers, and more, being fully utilizable through standard applications.
The Benefits of DPDK Adoption
Marvell’s wholehearted adoption of DPDK brought numerous benefits to both the company and its customers. Firstly, the transition between different silicon generations became seamless and predictable. Gone were the disruptions and compatibility issues that plagued the legacy code base approach.
By adhering to the standardized DPDK APIs, Marvell reduced its support burden significantly, as compatibility was ensured through the collaborative efforts of the DPDK community.
Moreover, Marvell’s adoption of DPDK enabled them to tap into the collective work of other partners and vendors within the DPDK community. This collaboration created a win-win situation, where Marvell could leverage the advancements made by others, while their contributions also benefited the community at large.
DPDK’s standardized library became the common language among Marvell’s customers, ensuring that requests for functionality tweaks adhered to DPDK compliance. This shift in customer mindset and adherence to the standard further enhanced the stability and scalability of Marvell’s solutions.
Furthermore, the adoption of DPDK opened up opportunities for Marvell to provide standard Red Hat support, which was previously challenging with their MIPS-based systems. Customers expressed a desire to run popular Linux distributions like Ubuntu on Marvell’s chips, prompting the company to embrace the open-source ecosystem fully.
By submitting kernel code and embracing open-source practices, Marvell gained access to comprehensive support from established Linux distributions, further strengthening their position in the market.
The Role of the DPDK Community Lab
Marvell acknowledges the significance of the DPDK community lab in enhancing the robustness of the project. While they don’t explicitly depend on the community lab for testing and validation, its existence contributes to the overall quality of the DPDK project.
The continuous validation and rigorous testing conducted in the community lab help identify and address bugs, ensuring that DPDK implementations are reliable and stable.
Marvell’s experience with DPDK has been positive in terms of stability and compatibility. The community lab’s rigorous testing and continuous integration and delivery (CI/CD) processes have played a crucial role in achieving this outcome.
The lab’s comprehensive testing frameworks and collaborative efforts have resulted in a mature and dependable DPDK framework, which Marvell and other contributors benefit from.
Conclusion
Marvell’s transition to DPDK illustrates the strength of open-source collaboration, standardization, and community engagement in streamlining support for their Octeon system-on-chip. By aligning with DPDK, Marvell overcame hardware compatibility issues, fostering a more versatile ecosystem.
This open-source commitment resulted in seamless transitions across silicon generations, creating a predictable application programming interface for customers.
The integration of Marvell’s accelerators into the DPDK community promoted innovation while preserving compatibility. The presence of the DPDK community lab improved the overall robustness of DPDK implementations, benefiting all contributors.
Marvell’s DPDK experience underscores the transformative power of open-source collaboration and the benefit of standardized libraries, positioning it as a leading provider of seamless silicon solutions in diverse domains such as 5G, enterprise security, and networking.
Check out the latest videos from Marvell at the DPDK 2023 Summit here.

Introduction
In the fast-paced world of telecommunications, companies are constantly seeking solutions to address evolving challenges and meet the demands of their customers. Ericsson, a global leader in the industry, has been at the forefront of incorporating new technologies into its product portfolio. One such technology is the Data Plane Development Kit (DPDK), which has proven instrumental in revolutionizing packet processing for Ericsson’s network infrastructure. This user story delves into Ericsson’s utilization of DPDK, the benefits it has brought, and the challenges associated with transitioning to a cloud-native environment.
Ericsson’s Shifting Landscape
Ericsson, a prominent vendor in the telecommunications domain, has a rich history of innovation and adaptability. With over 100,000 employees and a diverse range of products, Ericsson has witnessed a significant shift from traditional infrastructure to cloud-native solutions. As the industry embraces cloud-native architectures, Ericsson recognizes the importance of incorporating new technologies that align with this paradigm shift. DPDK, though not entirely new, has emerged as a critical component within Ericsson’s product portfolio, facilitating efficient packet processing and enabling the company to remain competitive in an evolving market.
Exploring DPDK’s Role
Niklas Widell – Standardization Manager at Ericsson AB, and Maria Lingemark – Senior Software Engineer at Ericsson shed light on the company’s adoption of DPDK. Maria, who has been involved in evaluating and utilizing DPDK since 2016, emphasizes the need for high-speed packet processing and the ability to split packet flows into multiple parallel streams. DPDK’s Event Dev implementation has been instrumental in achieving these goals, enabling Ericsson to process a large number of packets per second while maintaining the flexibility to distribute packet processing across multiple steps.
Transitioning from Specialized Hardware
Before incorporating DPDK, Ericsson relied on proprietary ASIC hardware to handle packet processing. However, the company recognized the need to shift toward more readily deployable commercial off-the-shelf (COTS) hardware solutions. DPDK played a crucial role in enabling Ericsson to transition from specialized hardware to a more versatile and scalable environment, reducing the reliance on custom solutions and increasing the reach of their offerings to a broader customer base.
Flexibility and Cost Efficiency
DPDK offers Ericsson the flexibility to deploy their packet processing solutions across a range of hardware configurations, both on ASIC hardware and on common x86-based platforms. By leveraging DPDK’s capabilities, Ericsson can scale their applications and efficiently utilize the available CPU resources. Moreover, the compatibility of DPDK with multiple drivers allows Ericsson to leverage hardware-specific features where available, enhancing performance and optimizing resource utilization.
Challenges of Observability and Cloud-Native Adoption
As Ericsson embraces cloud-native architectures, they encounter challenges related to observability, performance monitoring, and troubleshooting. Observing and comprehending the behavior of a complex system that processes packets in parallel across multiple CPUs and threads can be daunting. Balancing observability with performance optimization becomes crucial, requiring continuous refinement and adaptation. Additionally, the shift to cloud-based deployments necessitates rethinking observability strategies and ensuring seamless performance monitoring in these environments.
We needed to shift from doing packet processing on special purpose hardware, to doing it on cloud-based general compute hardware. DPDK enabled this – it created versatility and broadened external access. It significantly helped Ericsson meet our customers’ needs and demands as those changed in scale, and gave our team greater portability as well. And the ability to be able to reuse it across different departments without having to rewrite code was, and is, a significant benefit. – Maria Lingemark, Senior Software Engineer – Ericsson
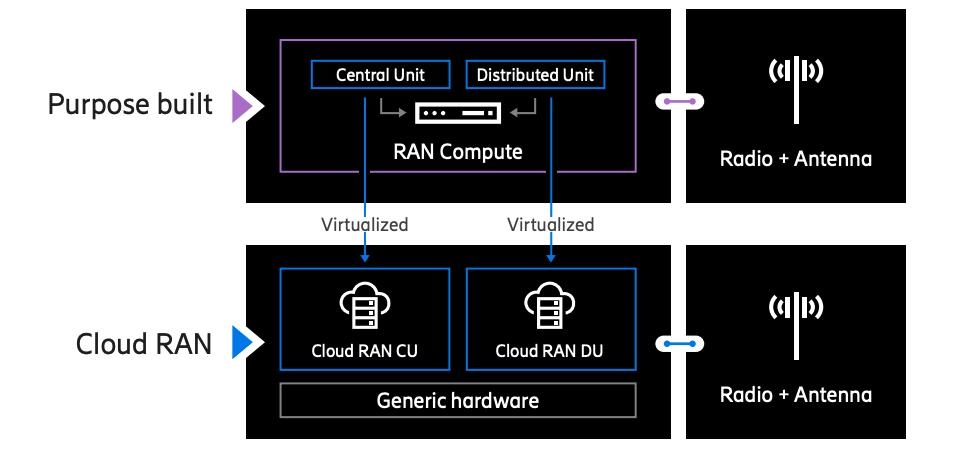
To tackle the observability challenges, Ericsson leverages the eBPF (extended Berkeley Packet Filter) integration in DPDK. By deploying eBPF programs within the DPDK framework, they have achieved efficient packet processing, improved throughput, and enhanced network visibility. The flexibility offered by eBPF allows Ericsson to tailor their networking solutions to specific use cases, ensuring optimal performance and resource utilization.
“Ericsson uses the included eBPF support in DPDK to simplify observability in complex cloud environments.” Anders Hansen, Cloud RAN System Developer – Ericsson
DPDK BBDev (Baseband Device)
DPDK BBDev (Baseband Device) plays a critical role in Ericsson’s ability to develop a portable and efficient Radio Access Network (RAN) implementation that seamlessly integrates with hardware acceleration from leading silicon vendors. This integration enables Ericsson to leverage the full potential of specialized hardware acceleration features offered by these vendors, enhancing the performance and efficiency of their RAN solutions.
By utilizing DPDK BBDev, Ericsson gains access to a standardized programming interface that abstracts the complexities of hardware-specific optimizations. This allows them to focus on developing high-performance RAN software while ensuring compatibility with various hardware platforms. The portability provided by DPDK BBDev enables Ericsson to deploy their RAN solutions across a wide range of hardware architectures, offering flexibility to their customers, while cultivating a heath ORAN eco-system in the industry.
“DPDK BBDev enables Ericsson to create a portable and efficient RAN implementation that is well integrated with HW acceleration from major silicon vendors” – Michael Lundkvist,
Principal Developer, RAN Application Architect – Ericsson
The integration of HW acceleration from major silicon vendors further boosts Ericsson’s RAN implementation. These hardware accelerators are specifically designed to offload computationally intensive tasks, such as FEC processing, resulting in improved throughput, lower latency, and reduced power consumption. By effectively utilizing these acceleration capabilities through DPDK BBDev, Ericsson delivers efficient and high-performing RAN solutions to their customers.
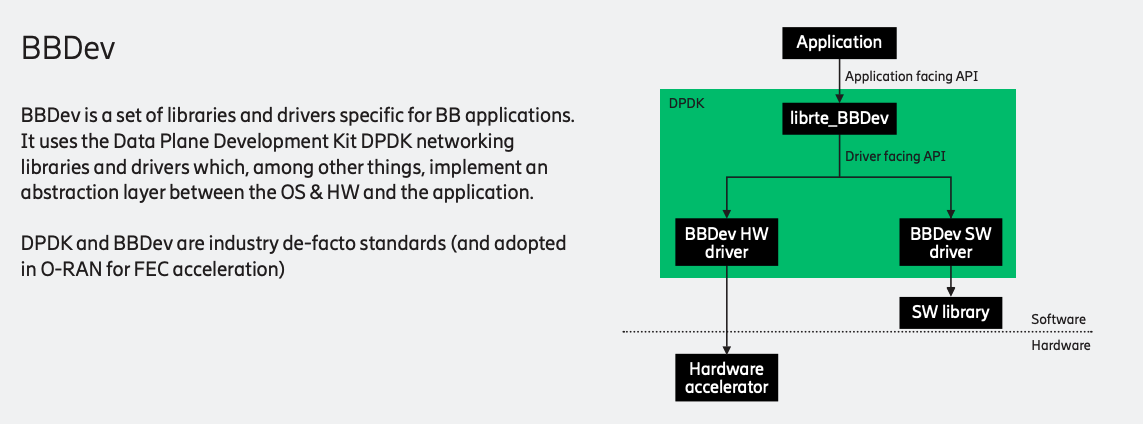
For more in-depth information on how DPDK BBDev enables Ericsson’s portable and efficient RAN implementation, you can refer to the white paper provided here. This white paper will delve into the technical details and showcase the advantages of integrating DPDK BBDev with hardware acceleration from major silicon vendors, offering valuable insights into Ericsson’s innovative RAN solutions.
DPDK and the Open Source Linux Foundation Community
————————————————–
Ericsson derives substantial benefits from its active involvement in both the open-source DPDK (Data Plane Development Kit) community and the larger Linux Foundation. By being an integral part of these communities, Ericsson experiences several advantages that contribute to their success and technological advancements.
First and foremost, being part of the DPDK community grants Ericsson access to a thriving ecosystem of contributors and developers focused on advancing high-performance packet processing. This access enables Ericsson to stay at the forefront of technological developments, leverage new features, and benefit from ongoing enhancements to DPDK. The collaborative nature of the open-source community encourages continuous innovation, allowing Ericsson to deliver cutting-edge solutions to their customers.
Engaging in the DPDK community also fosters collaboration and knowledge sharing with industry peers and experts. Ericsson can exchange ideas, best practices, and insights, benefitting from the collective expertise of the community. This collaboration helps Ericsson overcome challenges, improve their solutions, and accelerate their development cycles, all while contributing to the growth and success of the DPDK project.
Furthermore, Ericsson experiences a faster time to market by utilizing DPDK and collaborating within the community. By leveraging the work done by the DPDK community, Ericsson can capitalize on existing libraries, APIs, and optimizations, saving valuable development effort and resources. This efficiency enables Ericsson to bring their solutions to market more rapidly, meeting customer demands, gaining a competitive edge, and seizing market opportunities promptly.
Interoperability and compatibility are additional advantages that Ericsson enjoys through their involvement in the DPDK community and the larger Linux Foundation. DPDK’s emphasis on interoperability and common standards allows Ericsson to seamlessly integrate their solutions with other systems and platforms. This compatibility fosters a broader ecosystem, enabling Ericsson to collaborate effectively with other vendors and organizations, further expanding their market reach.
Participating in these open-source communities also positions Ericsson as an influential player and thought leader in high-performance networking and packet processing. Their contributions to the DPDK project not only enhance the framework’s functionality but also demonstrate their technical expertise and commitment to open-source initiatives. Ericsson’s influence and leadership within the community allow them to shape the direction and evolution of DPDK, driving the adoption of industry standards and best practices.
Lastly, being part of the larger Linux Foundation ecosystem offers Ericsson access to a vast network of organizations, developers, and industry leaders. This ecosystem provides collaboration opportunities, potential partnerships, and access to a network of expertise. By leveraging these connections, Ericsson can foster innovation, explore joint development efforts, and stay at the forefront of technological advancements in networking and telecommunications.

